안녕하세요. 오늘의집 커머스 서비스 Backend의 Software Engineer 멀린입니다. 이번 포스팅에서는 오늘의집의 MSA 전환 과정에서 개발한 Aggregator 공통 모듈에 대해 소개해 드리겠습니다.
Background
MSA 전환 phase 1 기간 동안 제가 속한 커머스 서비스 Backend의 주요 목표는 기존의 오늘의집 모놀리식(Monolithic) 서비스에서 저희 팀이 담당하고 있던 기능들을 Microservice 형태로 분리해 내는 것이었습니다.
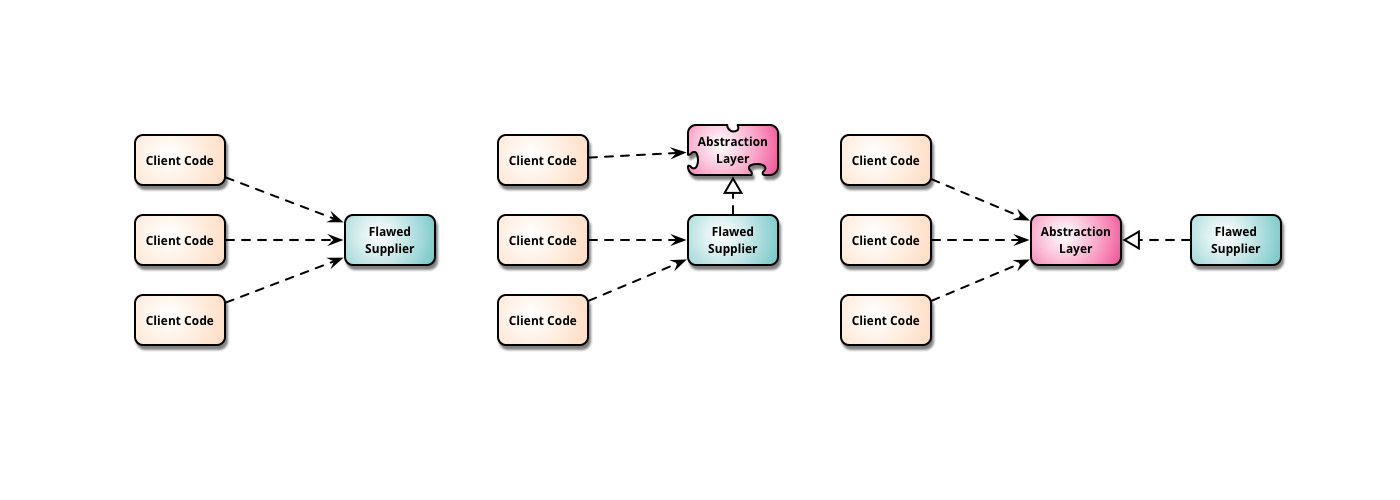
<오늘의집 MSA Phase 1. 백엔드 분리작업(클릭)>에서 소개한 것처럼 이 과정에서 저희는 원활한 전환을 위해 Branch by Abstraction 전략을 취하기로 했습니다.
 https://martinfowler.com/bliki/BranchByAbstraction.html)">
https://martinfowler.com/bliki/BranchByAbstraction.html)">Branch by Abstraction은 소프트웨어에 큰 변화를 줄 때 취할 수 있는 방법 중 하나로 위와 같이 Flawed Supplier와 Client 사이에 Abstraction Layer를 삽입하여 이후 Flawed Supplier를 쉽게 교체할 수 있도록 하는 방식입니다.
이러한 전략을 선택한 주요한 이유는 팀 간 의존성과 데이터 소유권 문제 때문이었는데요. 오늘의집 서비스는 크게콘텐츠, 커머스, O2O 그리고 물류 서비스라는 4개의 도메인을 가지고 있으며 이러한 도메인에 따라 서비스를 만들어나가는 팀도 분리되어 있습니다.
하지만 기존의 오늘의집 서비스는 하나의 거대한 Ruby on Rails 모놀리스 서비스에 모든 도메인과 프론트까지 함께 불편한 동거를 하며 일부만 작은 마이크로서비스 형태로 분리돼 붙어있는 형태였습니다.
더 큰 문제는 콘텐츠, 커머스를 모두 제공하는 서비스 특성상 도메인 간 데이터 조회가 필요한 케이스가 많음에도 불구하고, 모놀리스 서비스 내에서조차 도메인에 따른 분리가 잘 되지 않은 상태였다는 것입니다.
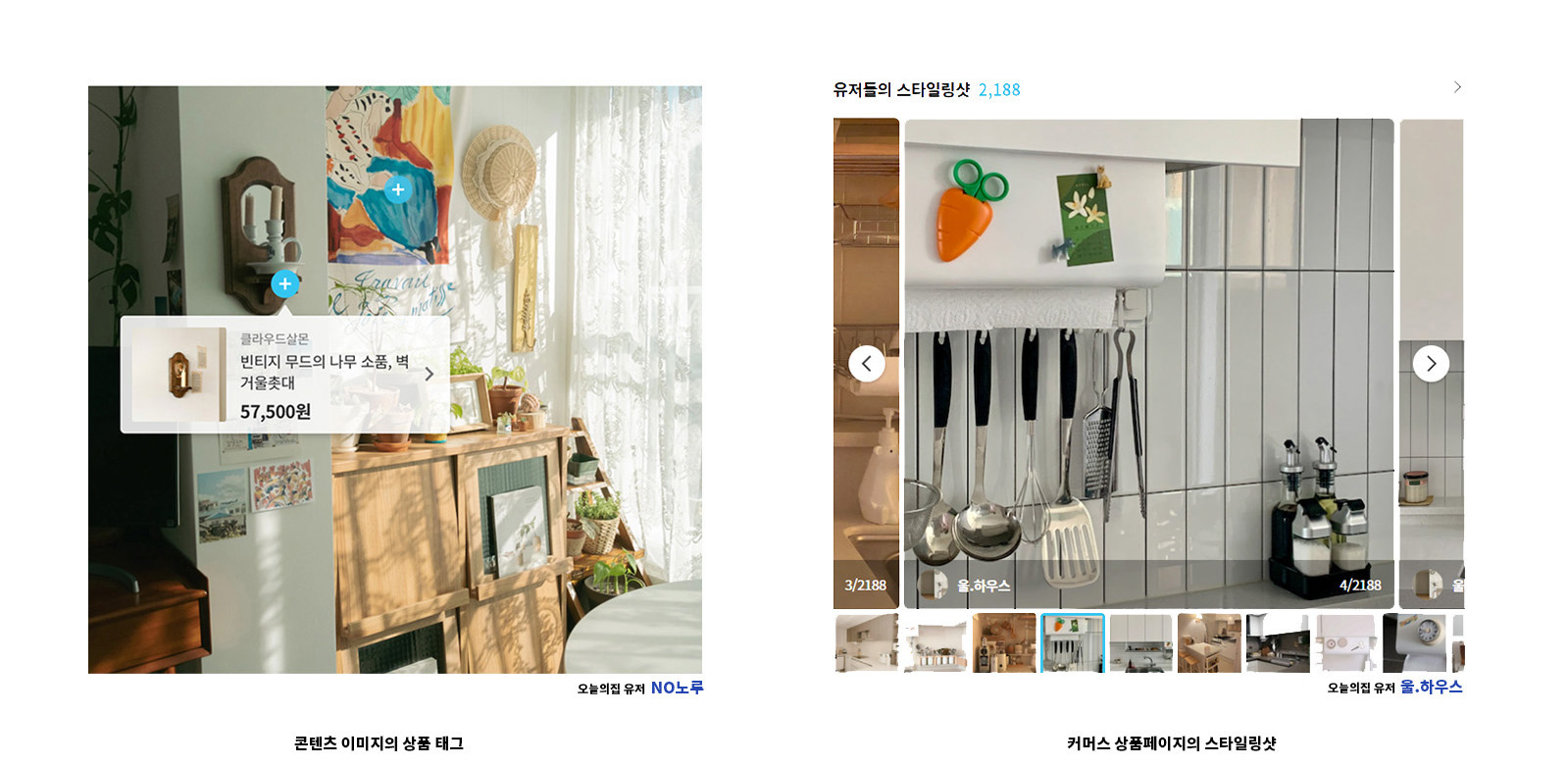
기존 모놀리스 서비스에서는 위 사진의 기능들과 같이 특정 데이터가 필요할 경우 그 자리에서 직접 DB를 조회하거나 도메인 구분 없이 모든 데이터를 함께 Join하여 가져오고 변경하는 등 분리하기 어려운 형태로 작성되어 있었습니다.
따라서 그저 Path 단위로만 커머스 영역을 분리하게 되면 여전히 다른 도메인 데이터에 접근하게 되는 바람직하지 않은 형태가 될 수밖에 없었습니다. 그래서 오늘의집 커머스 서비스 Backend팀에서는 분리한 레거시 커머스 서비스에서 외부 의존성을 전부 제거하기로 했습니다. 의존성이 제거됨에 따라 다른 마이크로 서비스에 존재하는 데이터를 가져오는 기능이 필요하게 되었습니다. 이를 위해 서비스 앞단에 Gateway를 두고, Gateway 바로 뒤에서 Branch by Abstraction 형태의 방법으로 다른 서비스의 데이터를 가져오는 Layer를 만들었는데요. 이를 위해 새롭게 추가된 모듈은 의존성 데이터들을 모아주는 기능에서 착안해 Aggregator로 명명하였습니다.
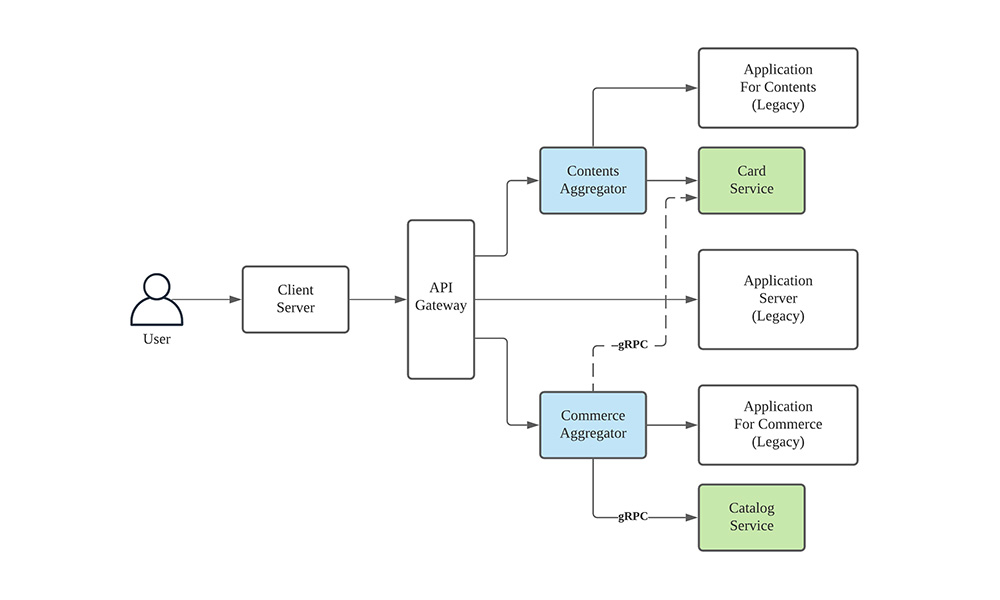
커머스와 콘텐츠팀 각각 Aggregator를 두어 커머스에서는 스타일링샷이나 스크랩, 좋아요 등의 정보를, 콘텐츠팀에서는 태그된 상품 정보 등을 요청하여 기존과 같은 API 응답을 유지할 수 있는데요.
여기까지 전환에 대한 계획은 세워졌고, 이제 Aggregator를 개발하기만 하면 되지만 문제는 Aggregator의 개발이 생각보다 간단하지 않다는 것이었습니다.
기존 모놀리스의 API들은 페이지 단위로, 하나의 페이지를 그리는데 필요한 모든 데이터를 하나의 API에서 전부 내려주는 방식으로 개발되어 있었습니다. 그러다 보니 API에 따라 몇 천 줄이나 되는 JSON Body를 갖는 경우도 있었고, 이 안에서 타 팀에 의존성을 가진 필드들을 전부 찾아서 API 종류별로 모아 데이터를 요청해야 하는 힘든 작업을 필요로 하고 있었습니다. (받아온 데이터를 다시 알맞은 곳에 넣어주는 작업 또한 API 별로 해줘야 하는, 상상만 해도 지치는 상황입니다 😅)
자연스럽게 이 같은 작업들을 자동으로 해주는 기능의 필요성을 느끼게 되었고 MSA 전환 기간 초반부에 걸쳐 Auto-Aggregation Module(가칭)을 개발하게 되었습니다.
Concept
Aggregator 서비스가 가진 역할은 위에서도 언급했듯이 다음과 같은 3가지 단계를 수행해야 합니다.
- 응답 내에서 의존성을 가진 부분을 탐색
- 의존성을 해소해 주는 타 팀 API에 따라 분류 및 요청
- 받아온 데이터로 응답을 변형(의존성의 해소)해 반환
이렇게 탐색, 요청, 해소의 3단계를 자동화하기 위해 다음과 같이 Resolver 인터페이스를 정의하였습니다.
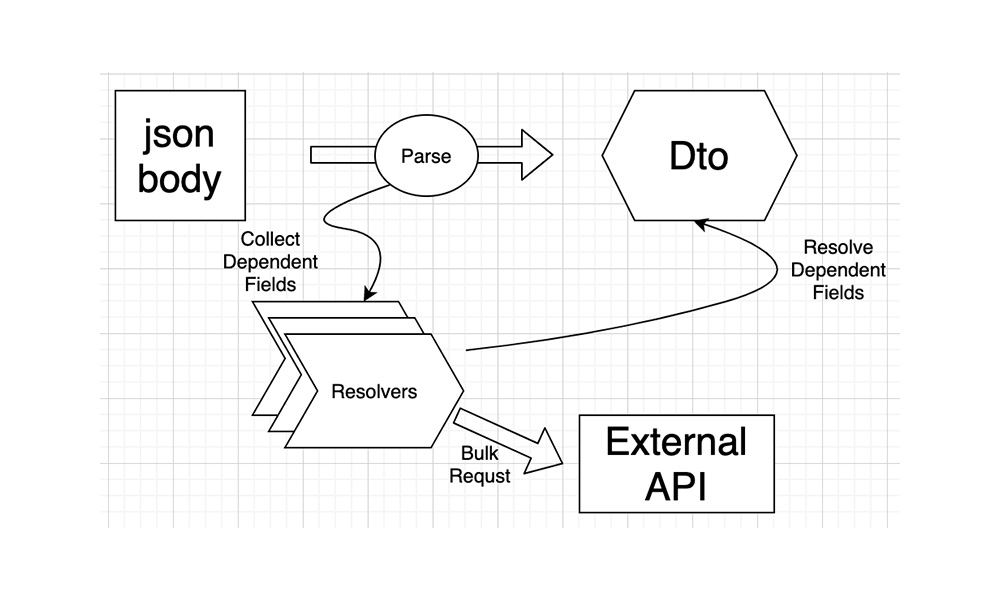
각각의 Resolver들은 특정 객체가 가진 의존성에 대한 요청과 해소를 담당해 주는 주체 역할을 하게 됩니다. JSON Payload를 파싱하는 과정에서 각 Resolver의 Queue에 해소해야 하는 Target 객체를 수집하고, 파싱이 끝난 후 각 Resolver들은 서로 비동기적으로 동작하면서 의존성을 해소하게 됩니다.
Interface
모듈의 개발에 있어 가장 중요하게 생각했던 부분은 사용자의 작업을 필요로 하는 Boilerplate를 최대한 줄이고, 공통 로직의 재사용성을 높이는 것이었는데요. 해당 모듈에서 제공하는 API를 사용하면 하나의 Path에 대한 응답을 파해서, 저장할 DTO(Data Transfer Object)와 해당 DTO 내의 의존성들을 해소할 Resolver들만 작성하면 작업이 끝나게 됩니다.
간단한 예시를 통해 인터페이스를 소개해 보겠습니다.
상품 DTO의 스크랩 정보 해소
@Resolvable
data class Product(
val id: Long,
var scrap: Boolean,
...
)
위처럼 상품 DTO의 Scrap 필드를 해소해 주어야 할 경우에는 Product를 Target으로 갖는 Resolver를 정의하면 됩니다.
@Resolver
class ProductScrapResolver(
val scrapService: ScrapService
) : FieldResolver<Product, Boolean>() {
suspend fun getFields(list: List<Product>): List<Boolean> {
return scrapService.getScrap(list)
}
suspend fun resolveTarget(target: Product, fieldVal: Boolean) {
target.scrap = fieldVal
}
}
FieldResolve <Target, Field>는 DTO의 특정 Field를 변경해 주기 위한 Resolver Abstract Class의 하나로, 내부에 Resolve 해야 할 Target을 담는 Queue를 갖습니다. FieldResolver의 구현은 Queue의 Target 목록을 변형하기 위해 필요한 Field 정보를 요청해 가져오는 getFields와 가져온 Field 정보로 각 Target을 변형해 주는 ResolveTarget의 두 단계를 갖게 됩니다.
이렇게 작성되어 모듈에서 제공하는 @Resolver, @Resolvable로 Annotate된 DTO와 Resolver Class들은 Aggregation Context Bean에 의해 수집되어 자동적인 Aggregation에 사용됩니다.
val body: String = webClient
.get()
.uri( ... ) //legacy endpoint
.retrieve()
.BodyToMono(String::class.java)
.awaitSingle()
val aggregated: Product = aggregationContext.readValue(body, Product::class)
위와 같이 Legacy Service의 응답 JSON String에 대해 Aggregation Context가 제공하는 Suspending ReadValue Function을 마치 ObjectMapper로 파싱하듯 적용하면, 작성한 Resolver들이 동작하면서 요청과 동시에 데이터 기입을 수행해 줍니다.
Additional Features
위에서 설명드린 인터페이스를 기본으로 코드의 재사용성과 서비스의 안정성, 성능 향상 등을 위해 여러 가지 추가적인 기능들을 구현했습니다. 간단히 정리하면 다음과 같습니다.
- Resolver 순서 지정 기능
기본적으로 서로 Asynchronous하게 동작하는 Resolver들 간 순서를 지정하여 특정 Resolver들이 모두 작동하고 나서 작동하도록 설정할 수 있다.
- Error Handling
각 Resolver 내에서 발생한 Exception Handling을 자유롭게 추가할 수 있다.
- HTTP Attribute 주입
Aggregator가 Proxy해주는 HTTP 요청과 응답 정보(HEADER, URI, BODY)들을 각 Resolver에 주입하여 구현 시 사용할 수 있다.
- Retry
동작 중 실패 시 Max Retry 회수를 Resolver 별로, 또는 일괄로 설정할 수 있다.
- Resolvable class 다형성 지원
Resolver의 Target Class를 Superclass로 갖는 DTO들에 대해서도 해당 Resolver가 작동한다.
이를 이용해 서로 모양이 다른 DTO에 대해서도 같은 Resolver로 처리할 수 있다.
- Spring Integration
Spring Bean들을 Constructor로 주입받아 각 Resolver 내에서 자유롭게 이용할 수 있다.
Under the hood
모듈의 개발에는 Spring webflux, Jackson, Kotlinx.coroutines, Java Reflections를 사용하였습니다. 여기에 추가로 Commerce Aggregator에서 해당 모듈과 함께 사용할 Spring Cloud Gateway와의 Integration을 위한 Extension들을 제공합니다.
모듈이 이러한 Library들을 사용해 어떻게 동작하는지를 간단히 정리해보겠습니다.
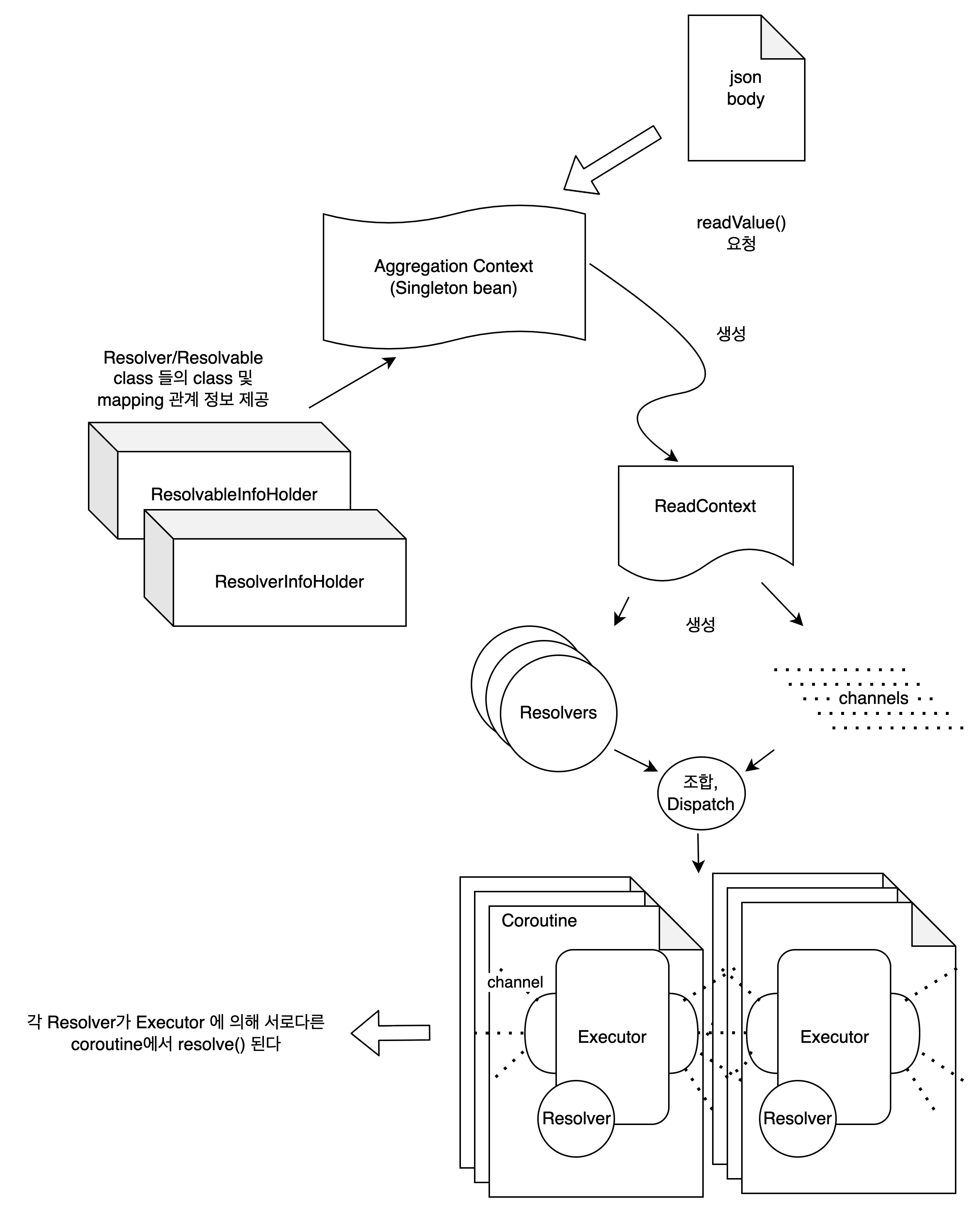
먼저 위에서 소개해 드렸듯이 AggregationContext Class의 Singleton Bean에서 전체적인 Aggregation 과정을 관리합니다. 이때 AggregationContext는 두 개의 InfoHolder Bean들로부터 사용자가 정의한 Resolver, Resolvable Class 정보를 제공받습니다. 각 InfoHolder들은 Java Reflections의 기능을 이용해 Class 정보를 Bean이 만들어지는 시점에 수집하여 갖게 됩니다. Class 정보 외에도 순서 관계, Retry 등의 기타 세팅 정보들 또한 수집하여 제공합니다.
이렇게 수집된 정보를 토대로 생성되는 Resolver들은 각 ReadValue 리퀘스트 별로 새로이 생성되고 사용되어야 합니다. 따라서 이러한 Resolver들의 생명주기를 관리할 수 있도록 AggregationContext는 ReadValue 요청마다 ReadContext를 생성하고, ReadContext가 Resolver들의 생성과 실행을 담당하게 됩니다.
Resolver들의 초기화가 끝나면 JSON Body로부터 해소가 필요한 객체들의 탐색과 수집이 이루어집니다. 객체의 탐색은 Jackson ObjectMapper가 Json을 파싱하는 과정을 Override해서 JSON 파싱과 의존성 탐색, 수집을 모두 한 번에 진행하도록 구현하였습니다. ObjectMapper에 Custom Deserializer와 Deserailizer Modifier를 등록하여 각 오브젝트가 파싱되었을 때 해당 Class의 오브젝트를 Target으로 갖는 Resolver들의 Queue에 해당 오브젝트를 넣어주도록 하였습니다.
수집이 끝나면 Queue가 비어있지 않은 모든 Resolver들은 서로 다른 Coroutine에서 ResolverExecutor에 의해 실행됩니다. Executor들은 서로 Kotlinx.coroutines Channel을 이용해 통신하고, 지정된 순서 관계에 따라 각 Resolver가 실행될 시점을 기다렸다가 종료 시 완료 이벤트를 공유합니다.
모든 Resolver의 작동이 끝나면 AggregationContext에서 변경된 DTO를 요청자에게 최종적으로 반환합니다.
그림으로 요약하면 다음과 같습니다.
Transition
모듈을 이용한 Aggregator의 개발을 마친 후 실 서비스 전환을 앞두고 다음의 세 가지 검증 단계들을 거치면서 Aggregator 응답 결과의 정합성을 검증하고 버그를 찾는 시간을 가졌습니다.
- Load Test
DevOps팀에서 구축해 주신 Production과 거의 동일한 테스트 환경과 Ngrinder 툴을 이용해 팀 내 동료 개발자분들께서 로드 테스트를 진행해 주셨습니다. 특히, 기존 Legacy 서버와 Aggregator의 성능 차이가 큰 만큼 두 서버의 적절한 Pod 비율을 찾는 것에 집중하였습니다.
- Traffic Shadowing
기존 서비스가 받고 있는 요청들 중 일부를 새로운 서비스에 똑같이 흘려주어 새로운 서버가 기존 요청들을 제대로 처리할 수 있을지 확인하였습니다. 이 과정에서 Platform팀에서 준비해 주신 두 서버 간의 응답 비교기능(Diffchecker)을 이용해 데이터 누락 및 변형을 잡아낼 수 있었습니다.
- Traffic Control
마지막으로 A/B 테스트 플랫폼을 이용하여 오늘의집 서비스로 들어오는 요청들을 신규 서비스로 전환을 진행하였으며 신규 서비스에서의 에러를 확인하며 점진적으로 트래픽을 전환하여 마침내 100% 전환을 이루었습니다.
Aggregator를 이용한 Monolithic To MSA 전환의 장점
1. 작업량이 적고 버그 발생 가능성 또한 낮습니다.
검증 단계에서 상당히 놀라웠던 점은 생각 이상으로 버그가 적게 발생했다는 것입니다. 이는 저희가 취한 전략의 특성상 Legacy 코드에는 최소한의 변경(의존성 제거)만이 이루어지기 때문에 기존 동작과 달라질 여지가 적었던 점이 작용했다고 생각합니다.
2. 새로운 기술의 도입 및 Tech Stack 전환에도 이점이 있습니다.
오늘의집에서는 기존 Ruby on Rails에서 Kotlin Spring으로 Tech Stack 전환이 이루어지고 있으며, 이번 MSA Phase 1을 기점으로 내부 마이크로서비스 간의 통신 프로토콜을 gRPC로 정하였는데요. Aggregator를 도입함으로써 gRPC로 새롭게 개발된 의존성 API들을 기존 RoR 이 아닌 Spring 기반 Aggregator에 도입하는 것이 가능해졌습니다.
3. 이후 진행할 MSA 작업에 있어서도 이점을 줍니다.
타 팀에서 제공받아야 할 (혹은 제공해야 할) API들을 미리 정리하고 개발해두었기 때문에 이후 남은 레거시를 리팩토링할 때에도 다른 팀과의 일정 조율이나 개발 요청 없이도 원활한 작업 진행이 가능해졌습니다.
이 외에도 모듈에서 비동기적인 Batch Get과 에러 핸들링에 대한 인터페이스를 지원하기 때문에 성능 면에서의 이점과 마이크로서비스 구조에서 발생할 수 있는 장애 전파에 대한 안정성도 얻을 수 있었습니다.
Future
오늘의집 서비스가 목표로 하는 최종적인 서비스 구조는 Backend Microservice들과 Client 사이에 BFF(Backend for Frontend) 서버를 두어 필요한 데이터의 수집을 담당하게 하는 것입니다.
아쉽게도 이번에 개발된 Aggregator 서비스들은 구버전 응답 유지 정도의 역할만을 하게 될 예정입니다. 하지만 약 4개월이라는 짧은 기간 안에 많지 않은 인원으로 전환에 성공했고 성능적인 검증 또한 마쳤기 때문에 Aggregator가 최종 형태에 도달하기까지의 중간다리 역할을 훌륭하게 수행해낼 수 있음을 보였다고 생각합니다. 이번 포스팅에서는 ‘모듈 개발기’라는 주제에 초점을 맞춰 소개해 드렸지만 모듈 개발과 이후 Aggregator의 개발, 테스트 등 이 모든 과정은 오늘의집 동료 개발자분들의 도움과 기여가 있었기에 가능한 일이었습니다.
개발된 Aggregator 모듈은 이후 기능을 조금 변경하여 Backend에서 맡게 될 Mobile BFF 서버의 개발에 사용할 계획이며, 타사에서도 오늘의집의 성공적인 MSA Phase 1을 참고할 수 있도록 오픈소스로 공개하는 것에 대해서도 논의 중에 있습니다. 공개하게 된다면 정돈된 코드와 문서로 다시 한번 소개해 드리도록 하겠습니다.
오늘의집 MSA Phase 2에서는 분리해낸 Legacy 서비스를 MSA 형태로 분리하고 BFF서버를 구축하는 작업이 진행될 예정인데요. 앞으로의 MSA 진행을 위해 오늘도 오늘의집 개발팀은 새로운 도전을 이어나가고 있습니다.
👨💻 오늘의집 개발팀을 더 자세히 알고 싶다면? (클릭)
