
안녕하세요. 오늘의집 플랫폼 백엔드 개발자 이언입니다. 오늘의집에는 CPC(Cost Per Click, 클릭당 과금) 광고 시스템이 도입되어 있습니다. 광고가 사용자에게 노출되고 사용자가 광고를 클릭했을 시만 미리 설정된 금액을 차감하는 방식인데요. 오늘 이 글에서는 오늘의집 광고 도입 과정 중 정산 시스템에 사용된 Kafka Streams에 대해서 설명드리려고 합니다.
📌 이 문서는 Kafka에 대한 기본적인 지식(topic, partition, offset)이 있다는 가정 아래 작성되었으며, 설명을 위한 시스템 요구 사항을 단순화하였습니다.
광고 정산 시스템 요구사항
- 광고주별로 예산 계좌를 부여합니다. 예산을 충전하면 그 금액만큼 예산에 더해주고 클릭 발생 시 CPC 금액만큼 예산에서 차감합니다.
- 광고주 ID가 주어지며 이를 가지고 예산을 찾아 요청에 따라 더하거나 빼는 시스템입니다. 예산은 실시간으로 조회가 가능해야 하고 매일 광고주별 클릭 통계를 제공해야 합니다.
- 클릭 요청은 (광고주 ID, CPC) 정보가 Kafka topic을 통해서 들어옵니다.
위에서 명시적인 요구 내용을 나열했는데 여기에 숨겨진 요구 사항이 있습니다. 바로 충전 요청은 요청당 한 번만 더해져야 하고 클릭 요청은 요청당 한 번만 빼야 한다는 것입니다. ‘당연한 소리’라고 생각하시겠지만, 그 당연한 기능을 어떻게 구현했는지 공유해 드리고자 합니다.
당연하지만 쉽지 않다.
당연하게 보이지만, 시스템을 구축하는 일은 쉽지 않음을 보여주는 유명한 트윗이 있습니다.

지금부터 백엔드 개발자에게 익숙한 RDB를 이용해 요구사항을 만족하는 정산 시스템을 설계해 보겠습니다. 이야기를 단순화 시키기 위해 예산은 이미 충전되어 있다는 가정 아래 클릭에 대해서만 이야기합니다.
RDB를 이용한 설계 1

- Kafka topic으로 클릭 정보(광고주 ID, CPC)가 들어옵니다.
- RDB에 광고주 ID로 현재 예산을 조회합니다.
- 조회한 예산 금액에 CPC만큼 차감해서 다시 RDB에 저장합니다.
- Kafka offset을 갱신합니다.
1~4번 과정이 문제없이 정상적으로 처리가 되었다면 offset은 6으로 101 ID를 보유한 광고주의 예산은 57500이 됩니다. 변경되는 영역은 offset과 예산 정보입니다.
만약 1,2,3번 과정은 정상적으로 처리되었는데 4번 과정에서 실패하였다면 정산 시스템은 offset 5에 해당하는 메시지를 다시 처리하게 되며, 이 경우 동일 클릭 요청을 두 번 처리하게 되어 중복 차감 문제가 발생합니다.
RDB를 이용한 설계 2
설계1에서 발생하는 중복 차감 문제를 해결하기 위해서는 동일한 클릭 요청이 두 번 들어오더라도 이미 처리한 요청인지 확인할 수 있는지 장치가 필요합니다. 이는 요청에 포함되어 있는 offset 정보를 이용해서 예산을 갱신할 때 이때 사용한 offset 정보를 같이 기록하는 방식으로 해결 가능합니다.

- Kafka topic으로 클릭 정보(광고주 ID, CPC)가 들어옵니다.
- RDB에 광고주 ID로 현재 예산, offset을 조회합니다.
- db의 offset과 message로 들어온 offset을 비교해서 이미 처리된 message인지 확인합니다. 이미 처리되었다면 5번 단계로 갑니다.
- 조회한 예산 금액에 CPC만큼 차감해서 offset과 함께 저장합니다.
- Kafka offset을 갱신합니다.
그러나, 이 방식은 비즈니스 로직 처리와 중복 방지 처리가 같이 구현되어야 하기에 서비스 로직에 집중하지 못하고 복잡해진다는 문제점이 존재합니다.
또 다른 문제점, 거래내역 저장
추가 요구사항으로 매일 광고주별 클릭 통계를 제공해야 하며, 이를 위해 클릭 요청 처리를 할 때마다 통계를 따로 저장해야 합니다. RDB에 일별, 광고주 ID를 key로 클릭 예산을 누적할 수도 있지만 통계 요구사항이 변경될 것을 대비해서 클릭 내역을 모두 저장해야 합니다. 다수의 클릭이 발생하면 매출은 높아지지만 RDB에 쌓이는 데이터가 많아지고, 주기적으로 내역을 다른 저장소로 옮기고 정리해야 한다는 문제점이 발생합니다.
더 나은 대안을 찾아서
Kafka에서 제공하는 Kafka Streams는 Kafka 클라이언트 라이브러리로 여러 기능을 제공합니다. 그 기능 중 하나가 바로 exactly-once 처리 지원입니다. 해당 기능은 메시지가 중복 처리 없이 단 한 번만 실행을 보장한다는 측면에서 정산 시스템에 꼭 필요한 기능입니다.

하지만 모든 환경에서 지원하지 않고, DB 등 외부 연동 없이 Kafka 내부 쓰기 작업만으로 데이터를 처리했을 시에만 exactly-once 하게 동작합니다.

정산 작업을 맡기 전 Kafka Streams에서 제공하는 exactly-once에 대해서 들었던 적이 있는데요. 이를 실제로 어떻게 사용할지에 대해서는 알고 있지 못했습니다. 지금부터는 단계별로 Kafka 만을 사용해서 시스템을 만드는 과정을 설명드리겠습니다.
in-memory DB(state store)
우선, 예산을 저장하기 위한 저장소가 필요하므로 RDB를 사용하는 시스템과 유사하게 시스템을 구성합니다. 단 RDB 대신에 시스템 내부에 in-memory DB를 띄워서 구성합니다.

RDB를 이용한 설계 1과 유사하지만, in-memory DB가 정산 어플리케이션 내에 있다는 점이 다릅니다. 이 구성은 장애가 생겨서 다시 실행되는 경우 in-memory DB에 저장된 데이터가 증발한다는 문제점이 발생합니다. 데이터 증발을 막기 위해 in-memory DB로 들어온 변경 내역을 로그로 남기고, 이를 파일로 남기는 대신 Kafka topic에 남깁니다. 그리고 다시 시작할 때 로그가 들어있는 Kafka topic을 읽어서 문제가 발생하기 전으로 복구합니다.
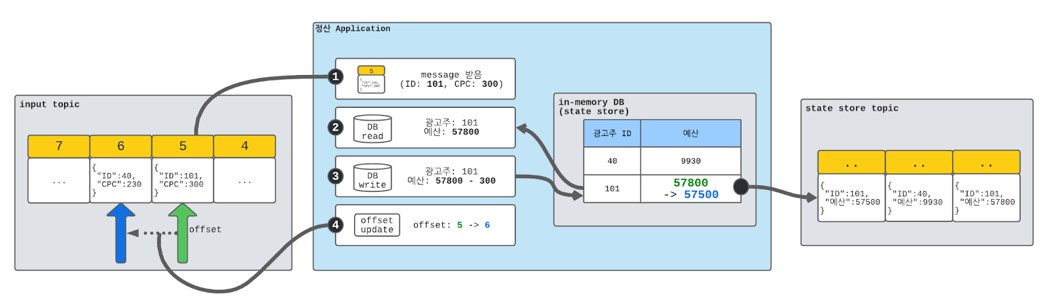
in-memory DB에 쓰기 작업을 통해 상태가 변경되면 변경 내역이 state store topic으로 전달됩니다. 이를 통해 시스템에 문제가 생겨도 topic에서 상태를 다시 읽어 복구할 수 있게 됩니다.
Kafka Transaction
여기에도 문제점은 있습니다. 로그를 남기는 작업(state store topic)과 offset을 갱신하는 작업이 atomic 하지 않다는 것입니다. 그러나 로그를 남기는 작업도 topic에 쓰는 작업이고 offset을 갱신하는 작업도 내부적으로 topic에 쓰는 작업입니다. Kafka에서는 이점을 이용해서 여러 topic에 쓰는 작업을 atomic하게 할 수 있는 Kafka transaction을 제공합니다. Kafka transaction을 이용해서 in-memory DB를 사용하면서도 문제가 생겨도 복구할 수 있는 시스템 구성이 가능합니다.
처리 내역 저장
클릭이 발생할 때마다 처리 내역(클릭 시각, 예산, CPC 금액)을 저장해 놓으면 나중에 이 정보를 활용해서 일별 통계, 월별 통계를 생성할 수 있습니다. RDB와 다르게 Kafka Streams를 이용할 때는 따로 외부 요청 없이 처리 내역 message를 처리 내역 topic에 생성하면 됩니다.
정산 작업
처리 내역은 처리 내역 topic에 쌓이고 Kafka connect(S3 sink connector)를 통해 보다 저렴한 저장소인 AWS S3에 저장합니다. 저장된 처리 내역은 Apache Spark을 통해 일별 통계를 생성해서 RDB에 저장합니다. 모든 거래 내역이 저장되어 있기 때문에 정산 규칙이 변경된다 하더라도 빠르게 대응할 수 있습니다.
Kafka Streams
복잡한 과정을 보시며 ‘그냥 RDB를 쓰지 이렇게 할 필요가 있나’라고 생각하실 수 있습니다. 그런데 이런 구성을 한 번에 제공하는 것이 바로 Kafka Streams 입니다. 동작 확인을 위해 간단하게 구현해 보았습니다.
입력으로 예산 변경 요청(+: 충전, -: 클릭 요청)을 받아서 예산을 갱신하고 거래 내역을 생성하는 작업입니다.
// stream processor 생성
final StreamsBuilder builder = new StreamsBuilder();
// 예산을 저장하는 state store 생성(in-memory DB + DB log)
final StoreBuilder<KeyValueStore<String, Budget>> storeBuilder = Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore(storeName),
Serdes.String(), budgetSerde);
builder.addStateStore(storeBuilder);
// 요청을 처리하는 stream 생성
KStream<String, Request> input = builder.<String, Request>stream("request", Consumed.with(Serdes.String(), valueSerde));
input
.transformValues(() -> new LedgerTransformer(storeName), storeName)
.to("ledger");
// Topology 생성 후 실행
final Topology topology = builder.build(properties);
final KafkaStreams streams = new KafkaStreams(topology, properties);
streams.start();
// 입력을 받아서 처리 내역을 생성하는 ValueTransformer
static class LedgerTransformer implements ValueTransformerWithKey<String, Request, String> {
private ProcessorContext context;
private String storeName;
private KeyValueStore<String, Budget> store;
public SimpleValueTransformer(String storeName) {
this.storeName = storeName;
}
@Override
public void init(final ProcessorContext context) {
this.context = context;
// statestore 생성
this.store = context.<KeyValueStore>getStateStore(storeName);
}
@Override
public Ledger transform(final String salesUserId, final Request request) {
// 광고주 ID에 해당하는 예산을 얻어온다.
Budget budget = store.get(salesUserId);
if (budget == null) {
budget = new Budget(0L);
}
// 예산에 요청을 더해서 새로운 예산을 만든다.
Long amount = budget.getAmount() + request.getAmount();
Budget newBudget = new Budget(amount);
// 새로운 예산을 저장한다.
store.put(salesUserId, newBudget);
// 처리내역을 생성한다.
return Ledger.newBuilder()
.setBudget(newBudget)
.setTimestamp(Instant.ofEpochMilli(context.currentStreamTimeMs()))
.setRequest(request)
.setSalesUserID(salesUserId)
.build();
}
@Override
public void close() { }
}
avro serializer, deserializer 등록, Kafka 환경 설정하는 부분을 빼면 전체 코드를 보여드렸는데요. 몇 줄의 코드만으로도 핵심 로직을 간단하게 구현할 수 있습니다.
실시간 예산 조회
Kafka는 topic별로 여러 개의 partition을 제공해서 처리량을 높입니다. Kafka Streams도 partition에 대한 기능을 제공합니다. 예산을 처리하는 processor가 topic 별로 여러 인스턴스에서 실행되고, 광고주의 예산 정보는 여러 인스턴스로 분산되어 저장됩니다.

예산을 조회할 때 어떤 인스턴스에 예산 정보가 들어있는지 알 수 있어야 조회할 수 있는데요. Kafka Streams는 interactive queries 기능을 통해 조회 기능을 제공합니다. 조회하는 key가 들어왔을 때 어떤 partition에 데이터가 들어있는지 확인하고, 해당 partition이 어떤 인스턴스에서 있는지 정보를 제공합니다.
Kafka Streams를 이용했을 때 장단점
장점
- exactly-once를 보장하기 때문에 로직에 집중할 수 있습니다.
- 외부 저장소와 통신하지 않기 때문에 빠르게 동작합니다. (간단한 테스트를 했을 때, 하나의 어플리케이션 인스턴스에서 초당 6만 정도의 처리량을 보였습니다.)
- partition 수와 어플리케이션 인스턴스 수를 키우면 처리량을 쉽게 높일 수 있습니다.
단점
- 기존과 다른 방식을 사용하는 것에 대한 거부감이 있습니다.
- 복잡한 SQL은 지원하지 못할 수 있습니다.
마치며
요구사항을 확인한 후, Kafka Streams를 이용하여 설계를 하고 검토를 진행했습니다. 솔직히 어느 정도 저항이 있을 거라고 예상하고 이것저것 준비했는데 오히려 논의를 통해 더 나은 설계로 갈 수 있었습니다. 회사에 자유로운 토론 문화가 있어서 가능했던 것 같습니다. 개인적으로 이 프로젝트를 통해 많은 것을 배울 수 있었으며, 함께 프로젝트를 진행한 동료들에게 감사의 인사를 전합니다.
👨💻 오늘의집 개발팀을 더 자세히 알고 싶다면? (클릭)
📝 관련 문서
