
안녕하세요. 오늘의집 프론트엔드 개발자 끼로입니다. 테크 리드 진식 님이 소개해준 ‘오늘의집 MSA 여정 Phase 1. 전환전략(클릭)’에 이어서, 저는 MSA 전환을 위한 사전 준비로 프론트엔드 측면에서 무엇을 진행했는지 공유하고자 합니다. 오늘의집의 현재 서버는 Ruby on Rails로 개발된 모놀리식 구조로 되어있어서 서버가 굉장히 많은 일들을 담당하고 있는데요. 이 글에서는 현재 서버에서 어떻게 클라이언트 코드를 분리할 수 있었는지 그 과정을 소개합니다.
개요
오늘의집의 서비스는 DB에서 데이터를 가져와서 JSON을 만들고, React 페이지를 HTML로 내려주는 등 백엔드 쪽에서도, 프론트엔드 쪽에서도 여러 가지 일을 하고 있습니다.
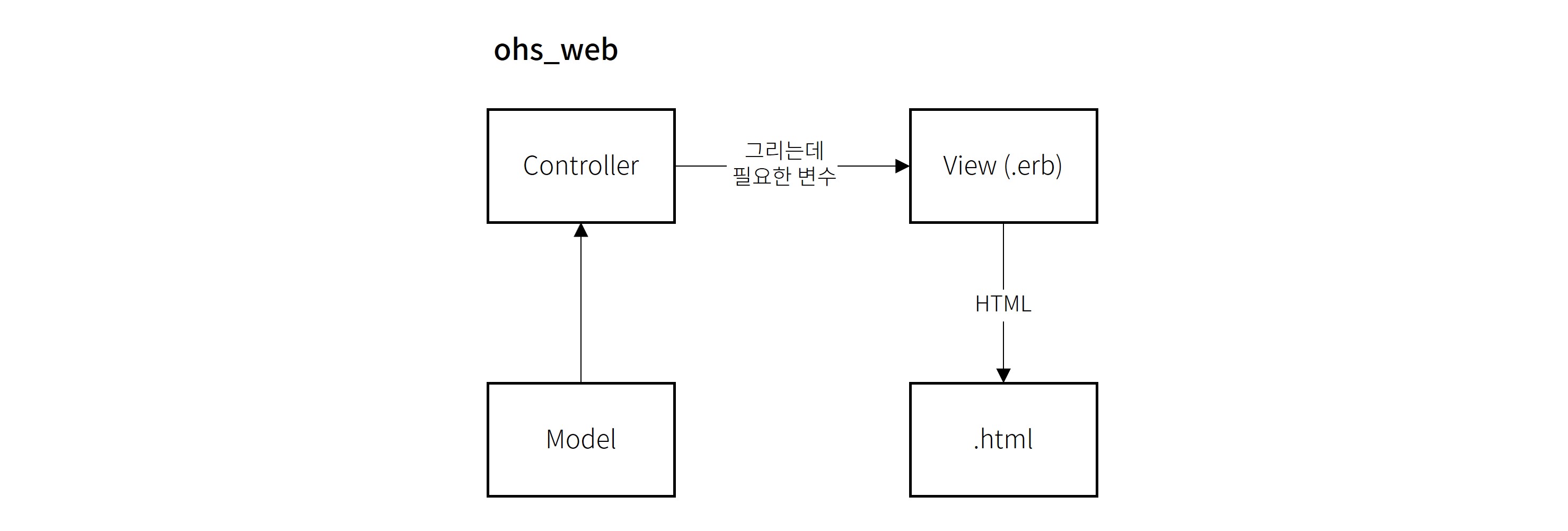
오늘의집 서비스는 초기에 Ruby on Rails 를 채택하여 구축하였고, 이 프레임웍에서 크게 벗어나지 않는 형태에서 지속적인 개선(개발)을 해왔기 때문에 그동안은 컨트롤러에서 DB 내용을 끌어온 뒤 .erb라는 템플릿 언어로 HTML을 그리는 형태를 벗어난 적이 없었습니다. 심지어 JSON을 그릴 때도 이 방식을 벗어나지 않고, .jbuilder라는 다른 템플릿 언어로 JSON을 그리게 되어 있습니다.

그래서 오늘의집에 React를 붙이게 되었을 때도 이 방식에서 크게 벗어나지 않았습니다. 사실상 React를 PHP/JSP 같은 템플릿 언어로 쓰는 것과 별반 다를 게 없이 erb에서 자바스크립트 런타임을 호출해서 React에 렌더링을 요청하는 형태였습니다. 이렇게 구현해도 클라이언트에서는 딱히 제한이 없으므로 이 구조 위에서도 SPA 기반의 여러 가지 기능들을 계속해서 구현해올 수 있었습니다.
클라이언트 서버를 만드는 이유
서비스 전체의 MSA 과업을 준비하면서 클라이언트가 가져가야 하는 관심사와 서버가 가져가야 하는 관심사가 서로 다름에도 불구하고, 하나의 Ruby 서버에서 다양한 과업이 수행되다 보니 서로의 관심사가 엮이는 일이 발생하였습니다. 또 Ruby를 Kotlin + Spring 기반으로 변환할 때도 서비스 단위로 클라이언트를 분리할 수 있어야 하였는데 그런 때에도 하나의 Ruby 서버에서 클라이언트 코드를 모두 관리하고 있기 때문에 서비스 단위로 클라이언트를 분리하기 어렵다는 문제가 발생하고 있었습니다.
한편으로 클라이언트 자체에서는 Ruby에 의존성을 지니다보니 개발 환경 구성이 어려워질 뿐만 아니라, 클라이언트 로직과 관련된 내용에 대한 서버 수정이 필요할 때 Ruby 코드를 수정해야 하는 등의 이슈가 생기고는 하였습니다.
따라서 클라이언트 코드가 독립적으로 움직일 수 있는 클라이언트 서버 환경을 구축하면서, 백엔드의 라이프사이클과 클라이언트의 라이프사이클이 서로 다르게 움직일 수 있게 하고 서비스 단위로도 클라이언트가 분리될 수 있도록 하는 게 이번 클라이언트 서버 분리 과업의 주요한 목적이었습니다.
사전 준비
몇 년 전의 오늘의집 클라이언트 코드는 Ruby on Rails에서 제공하는 .erb와 같은 템플릿 언어와 React같은 프레임워크를 사용하지 않고 jQuery를 사용하고 있었기 때문에 동적인 컨텐츠를 그리는데 어려움이 많았고, 프론트엔드 개발자에게 Ruby on Rails에 대한 지식이 필요하다는 문제도 있었습니다. 이 때문에 Ruby on Rails에 대한 지식 없이 개발하기 수월하고, 복잡하거나 동적인 페이지를 개발하기 편리한 React로 전환하기로 결정했습니다. 이를 진행하기 위해 신규 기능이 추가될 때나 페이지가 개편될 때마다 페이지 단위로 꾸준히 React로 리팩토링하고 있었습니다.
React로 다시 개발하면서 Ruby의 CSS/JS 코드나 .erb 템플릿 코드를 최대한 참조하지 않도록 몇 년 동안 꾸준히 작업해오다보니 Ruby에 대한 의존성이 사라져 클라이언트 서버를 분리하는 것을 고려할만한 시점이 되었습니다.
신규 기능이 추가되지 않아서 리팩토링된 적이 없던 몇몇 페이지들은 여전히 레거시로 남아있어 클라이언트 서버 분리에 발목을 잡았고, 이 페이지들은 모든 프론트엔드 개발자분들이 같이 작업해주셔서 모두 React로 전환할 수 있었습니다. 마침내 Ruby쪽 코드에 의존하는 부분이 모두 사라지게 되었고, 클라이언트 서버 분리를 할 수 있게 되었습니다.
도전해야 할 과제들
하지만 분리하는 것도 쉽지 않았습니다. 개발을 아예 멈출 수 없는 상황에서 클라이언트 서버를 분리해야 했기 때문에 신규 작업에 대해서 클라이언트 서버와 Ruby 서버 양쪽 모두 정상적으로 작동할 수 있도록 개발해야 했습니다.

문제는 이뿐만이 아니었습니다. git 저장소 또한 새 저장소로 바로 넘어갈 수 있는 것이 아니라, 양쪽에서 지속해서 개발이 이루어지면서 검증할 수 있어야 했기 때문에 루비 저장소와 클라이언트 저장소 둘 다 동시에 커밋하고 동기화할 수 있는 방법이 필요했습니다.
git subtree
위와 같은 문제를 해결하기 위해서 git subtree라는 걸 사용했습니다. git subtree를 사용하면 저장소의 특정 폴더만 모든 히스토리를 보존한 채로 들고나올 수 있습니다. 물론 다시 히스토리를 합치는 것도 가능합니다.

하지만 이렇게 subtree를 사용하면, ohs_web 쪽에서 커밋이 2개로 복사되는 현상이 발생하게 됩니다. app/javascript 폴더 안의 커밋, 그리고 바깥의 커밋으로 나누어지기 때문인데요. 이 현상에 문제가 있을까 생각해 봤을 때, Github 잔디밭이 더 진해진다는 문제점(^^a)을 빼면 딱히 없고 subtree가 주는 장점에 비해서 사소한 이슈라 판단되기 때문에 subtree를 사용하기로 결정하였습니다.
마지막으로 subtree 사용 시 동기화를 쉽게 하는 것이 관건이었는데요. 각 레포에 동기화 스크립트를 만들어 넣고, GitHub Actions를 활용해서 자동으로 동기화가 가능하도록 구현했습니다. 아쉽게도 아직 실행은 수동이지만요.
이렇게 하여 저장소를 그대로 가지고 나오는 것은 해결됐습니다! 하지만 들고 나온 폴더에는 서버 코드가 없어서 정상적으로 구동되지는 않았습니다.
클라이언트 서버 만들기
클라이언트 서버는 단순히 HTML/JS/CSS 같은 정적인 리소스를 내려주는 정도로 해결하는 경우도 굉장히 많습니다. 이렇게 하면 S3와 CloudFront 같은 CDN을 활용해서 프론트엔드에서 관리할 서버 없이 간단하게 서비스를 운영할 수 있는데요. 하지만 서버 사이드 렌더링, 즉 서버에서 HTML을 만들어서 내려주는 것이 안 되기 때문에 Next.js 같은 오픈 소스 개발 프레임워크를 활용하는 경우도 많습니다.
문제는 오늘의집 코드베이스가 애초부터 Ruby 서버에 의존하는 형태로 만들어져 있었기 때문에 오픈 소스를 그대로 사용하는 것도 무리가 있다는 것이었습니다.
- 먼저 모든 REST API 호출을 api.example.com 같이 다른 도메인을 사용하지 않고, HTML이 서빙되는 도메인과 같은 도메인에서 호출하게 되어 있었습니다. 이를 사용하는 API가 너무 많아 모두 수정할 수는 없었기 때문에 간단하게 REST API에서 사용하는 JSON 형식의 요청이 들어오면 Ruby 서버로 프록시를 보내도록 했습니다.
- 다음은 쿠키 이슈입니다. 모든 인증이 Ruby 서버에서 만들어준 쿠키에 의존하기 때문에 이것도 프록시를 활용할 수밖에 없었습니다.
- 프론트엔드 코드베이스도 Ruby 쪽에서 개발한 react-rails와 같은 구조에 의존하기 때문에 커스텀 없이 그대로 사용하기에 어려움이 많았습니다.
즉, 프론트엔드 쪽만 들고 나오고 다른 부분은 무조건 Ruby 서버에 의존하는 형태로 개발할 수밖에 없었습니다.
react-rails란?
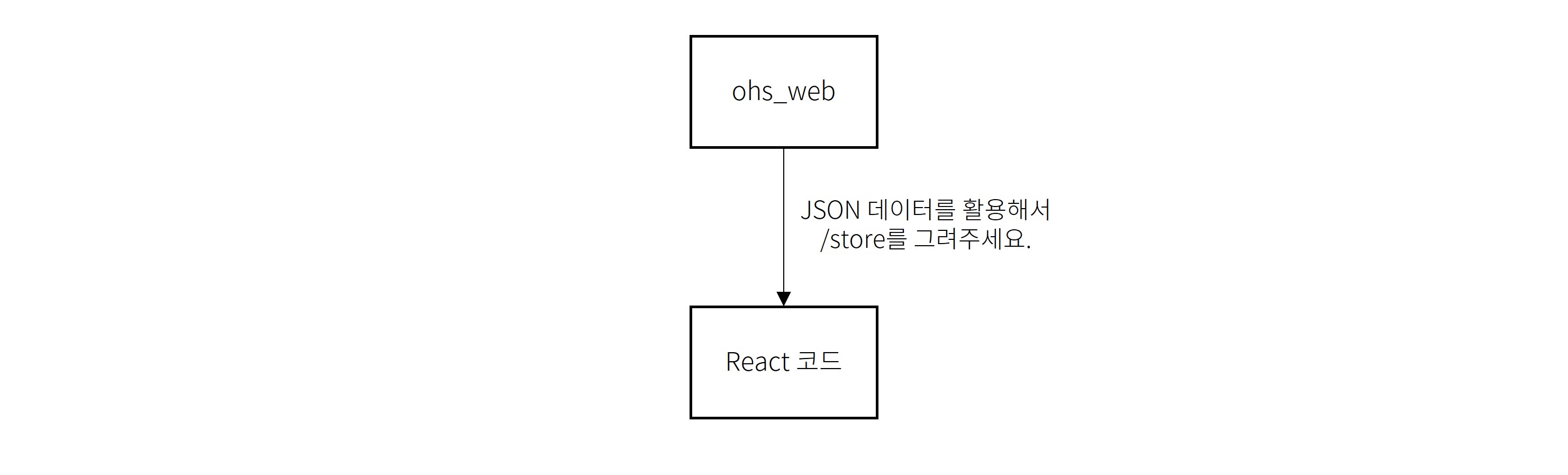
react-rails를 간단하게 정리하자면, Ruby 서버에서 특정 페이지를 그려달라고 요청하면 React에서 그려주는 것인데요. 문제는 보시다시피 렌더링을 위한 정보를 전부 Ruby 서버가 가지고 있다는 점입니다. 다시 말해서 어떤 페이지를 React로 그릴 수 있는지, 어떤 JSON이 필요한지, API 버전은 몇인지 등의 정보를 전부 다 Ruby 서버가 가지고 처리하는 식입니다. 이런 정보를 클라이언트 서버가 얻어낼 수 없다면 클라이언트 코드만 가지고 렌더링하는 것도 불가능합니다.
클라이언트 서버 플로우
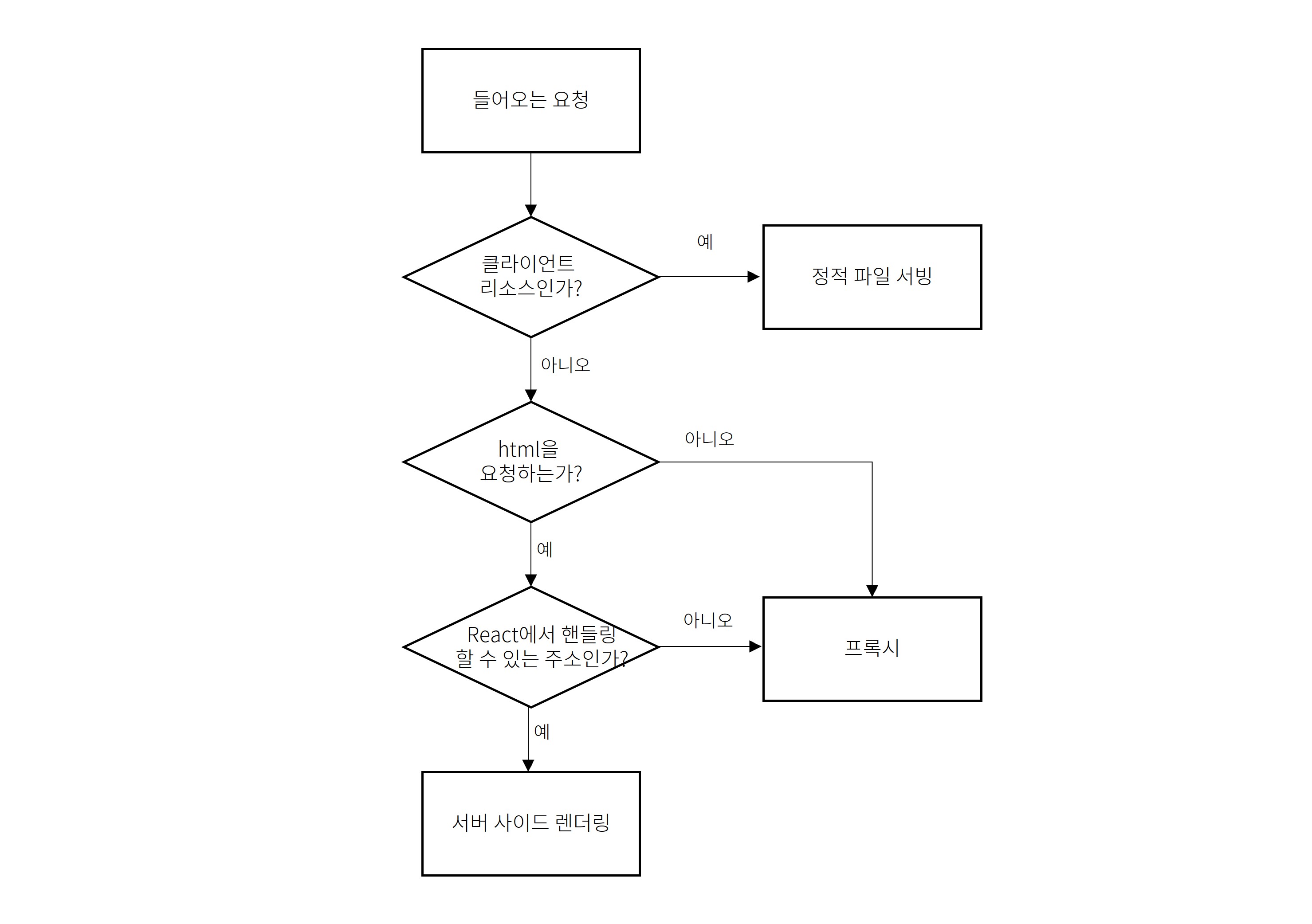
이런 렌더링을 위한 정보를 클라이언트 서버에서 얻어낼 수 있다면, React로 그릴 수 있는 부분은 React로 그리도록 하고 나머지는 전부 프록시를 활용해서 Ruby 서버로 보내도록 하는 방법이 가능합니다. 즉, React에서 핸들링 가능한 내용만 필터로 걸러내고 아닌 것은 전부 Ruby 서버로 보내는 방식입니다.
이렇게 핸들링할 수 있는 주소를 추출하기 위해 여러 방법을 고민해 봤는데 기존에 SPA(single-page application/단일 페이지 어플리케이션)로 오늘의집을 전환하면서 비슷한 고민을 했던 적이 있어 이 방법을 이용해서 클라이언트 서버를 구현하기로 했습니다.
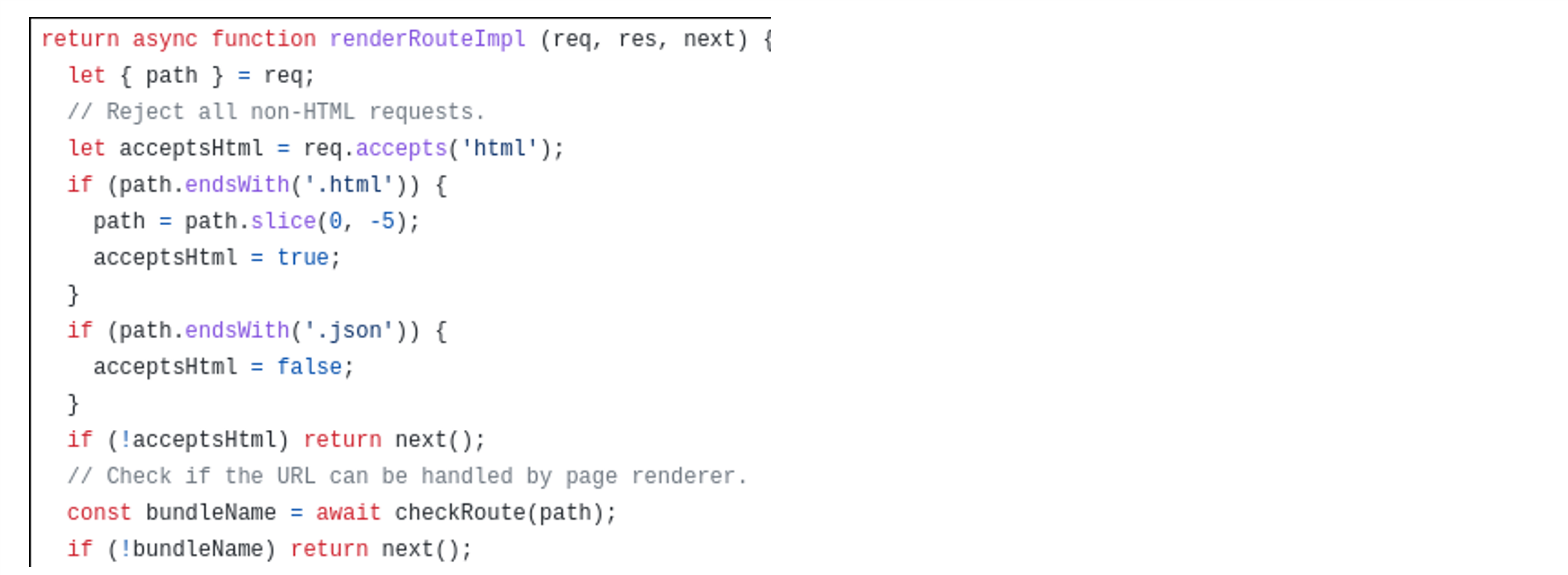
SPA로 넘어가기 위해 썼던 방법
SPA를 사용하면 HTML을 새로 불러오지 않고 페이지가 바뀔 때 자바스크립트에서 단독으로 모든 로직을 제어하게 됩니다. 오늘의집 클라이언트에서는 기존에도 SPA를 적용했던 적이 있는데요. 이를 위해서는 React가 그릴 수 있는 모든 경로를 하나의 변수로 모아두고, 자바스크립트 혼자서 처리 가능한지 계속 판단하는 로직이 필요했습니다.
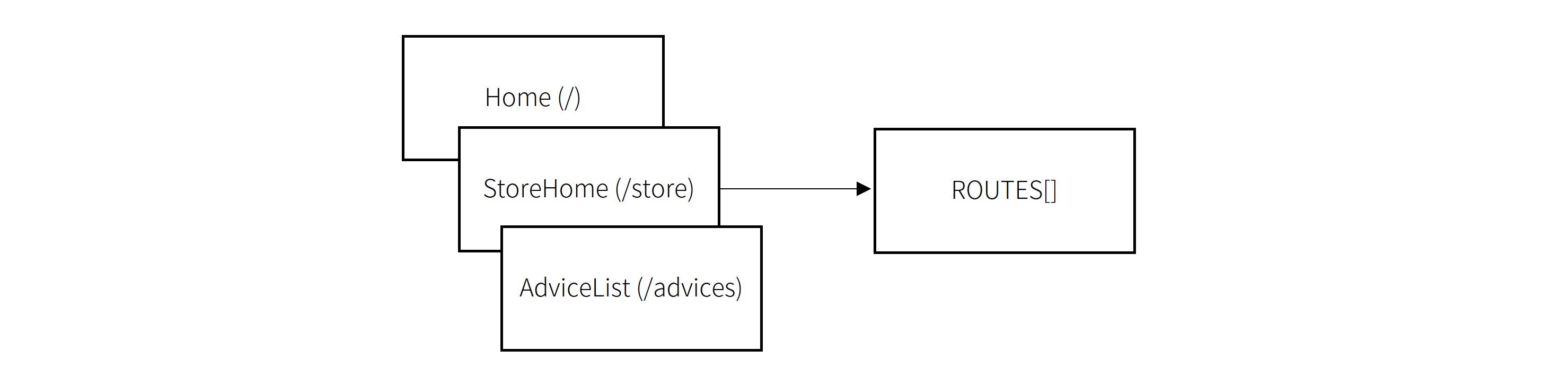
그래서 이렇게 경로들을 모아두고 이 URL(/store)이 자바스크립트에서 처리가 가능하면 HTML을 새로 부르지 않고 처리하는 방식으로 구현했습니다. 지금은 이 로직이 클라이언트 내부적으로만 쓰이고 있지만, 이걸 그대로 활용하면 클라이언트 서버에서도 어떤 URL이 처리 가능한지 쉽게 알 수 있습니다. 또한, 어떤 API 버전이 필요한지를 따로 마킹해두면 클라이언트 서버에서도 이를 사용해서 버전에 맞는 API를 호출해줄 수 있습니다.
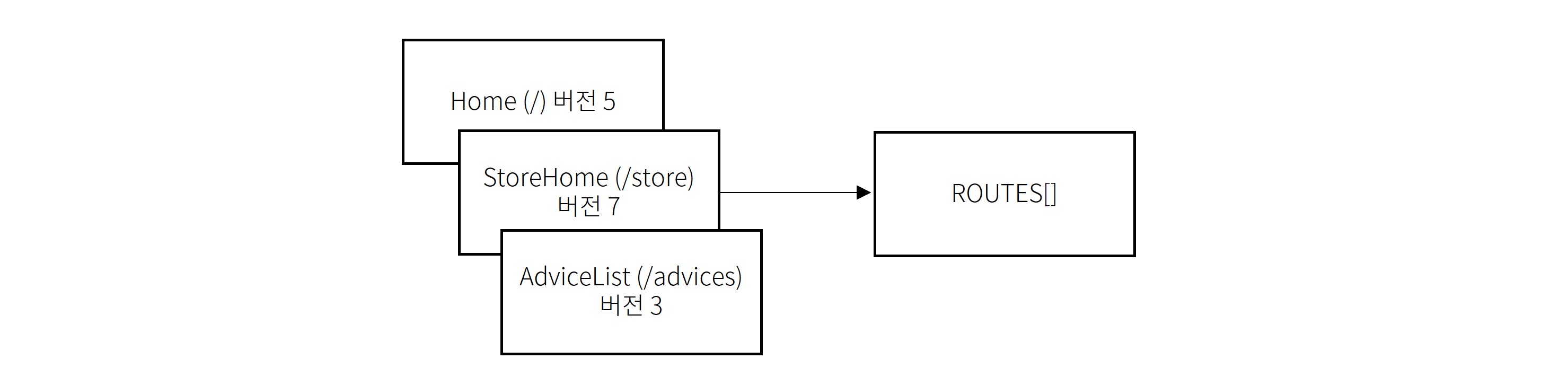
주소 정보 추출하기
문제는 이 데이터가 클라이언트 번들 속 깊숙한 곳에 있어서 서버에서 쓸 수 있게 꺼내오려면 굉장히 복잡한 과정을 거쳐야 한다는 점입니다. 원래 서버에서는 클라이언트 번들 JS를 샌드박스 안에서 돌리면서 SSR을 위한 렌더링 요청하게 되어 있는데요.

여기서 SSR과 별개로 추가로 사이트 맵을 출력하는 메소드를 글로벌에 노출시키고, Node.js 서버에서 이 메소드를 호출하는 방법으로 사이트 맵을 추출하도록 했습니다.


최종적인 플로우
이렇게 Ruby 서버를 흉내 내면서 프론트엔드를 그리기 위한 모든 준비가 끝났습니다. React로 그려야 하는 내용을 요청했을 때, 간단하게 아래처럼 Ruby 서버가 하는 일을 그대로 흉내 내주면 됩니다. Ruby 서버는 필요한 정보를 DB나 다른 부분에서 가져와서 모두 준비되면, 템플릿 언어로 HTML을 그리는 형태로 되어 있습니다. 이와 비슷하게 클라이언트 서버에서는 그리는데 필요한 정보들을 미리 API를 호출해서 취합하고, 이를 React로 보내서 HTML을 그리는 식으로 구현할 수 있습니다.
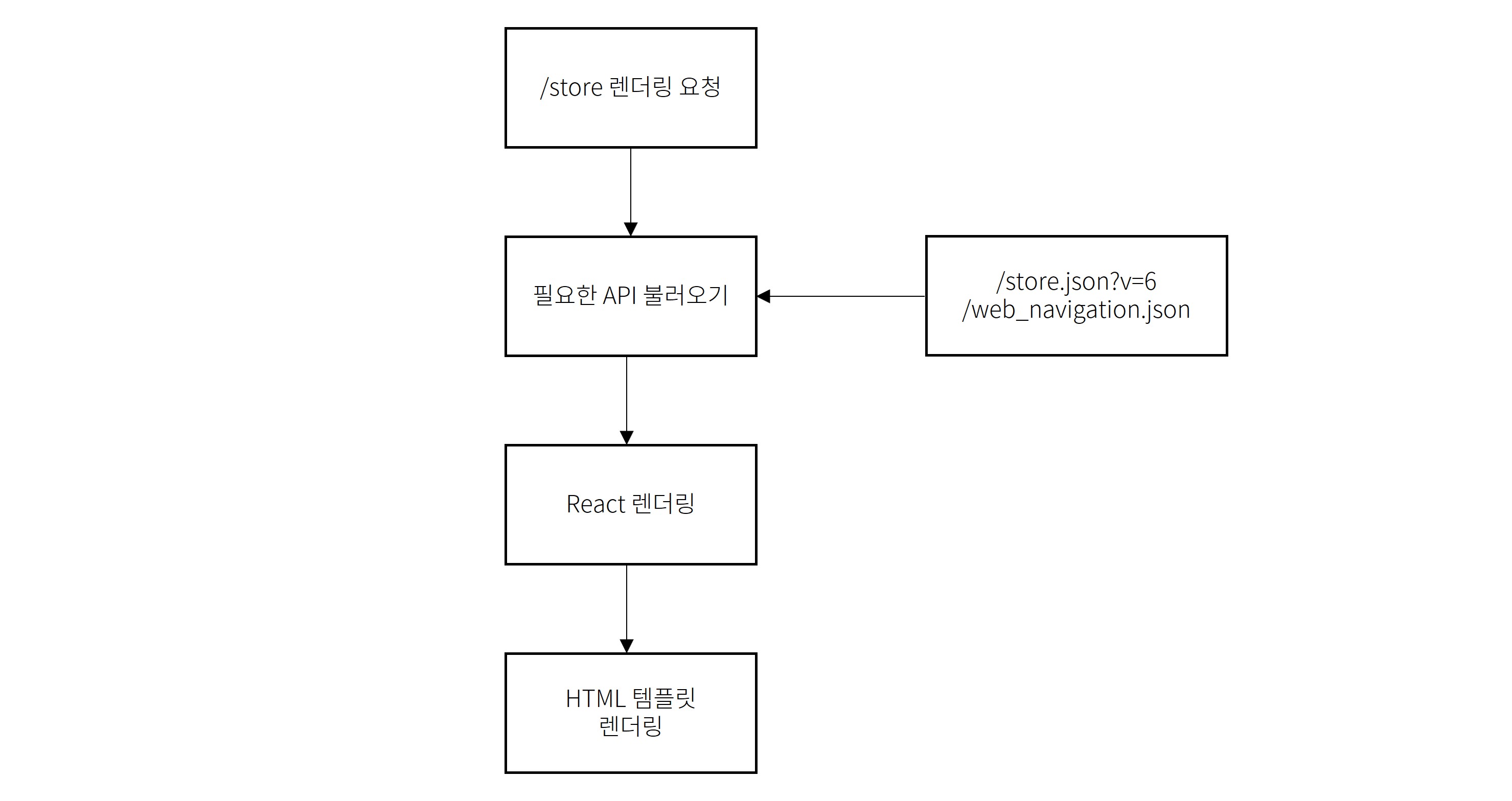
개발 서버와 프로덕션 서버
다음 단계는 이 서버가 개발 환경에서도 사용할 수 있어야 한다는 점인데요. 프로덕션 환경에서는 이미 빌드된 JS 파일을 사용하면 되지만, 개발 환경에서는 webpack(프론트엔드 번들링 도구)을 실시간으로 실행하면서 구동할 수 있어야 했습니다. 이를 위해서 static provider와, webpack 두 가지 소스에서 따로 JS 번들을 받아올 수 있게 하고 개발 환경에서는 webpack을 프로덕션 환경에서는 static provider를 사용하도록 구현했습니다.
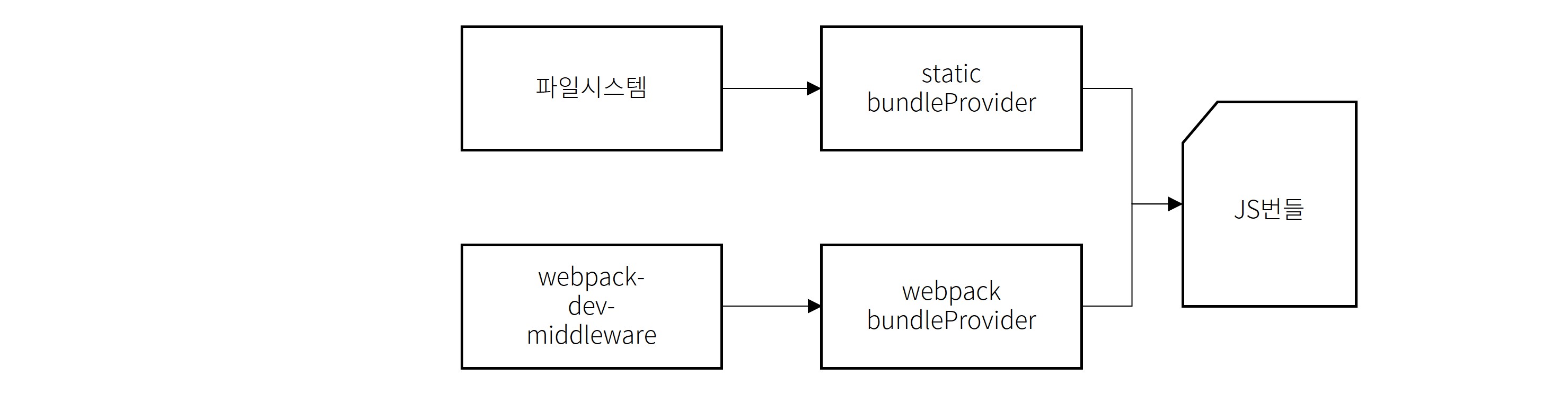
병렬 처리
Node.js는 비동기 I/O로 인해 빠르지만 정말 치명적인 단점을 가지고 있습니다. 자바스크립트를 싱글 스레드로 돌리기 때문에 CPU를 많이 쓰는 작업이면 CPU 코어를 하나 밖에 쓰지 못합니다. React 렌더링은 CPU를 많이 쓰는 작업이기 때문에 Node.js를 그냥 쓰면 동시에 요청을 하나밖에 처리하지 못합니다. 이를 해결하기 위해서 React를 렌더링하기 위한 스레드 풀을 구성하고, 렌더링을 하려고 할 때마다 잠시 빌려서 쓰는 방식으로 동시 처리량을 늘리도록 했습니다.


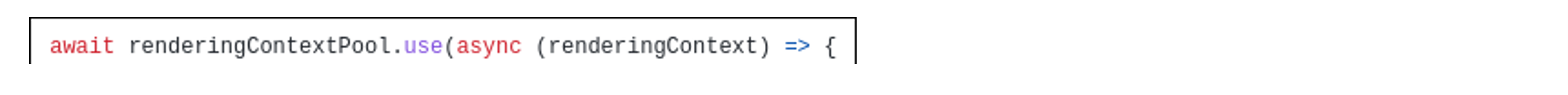
마치며
이렇게 이런저런 허들을 넘어서 프론트엔드 서버를 구현하게 되었습니다. 프론트엔드 서버를 분리하고 나면, 프론트엔드에서도 각 서비스별로 서버를 분리하는 것이 수월해지고, 백앤드 서버를 구축할 때 클라이언트 서버가 가리키는 API 서버를 바꾸는 방법으로 Ruby가 아닌 다양한 기술로 구성하는 것이 가능해집니다.
즉, 이 작업이 MSA로 넘어가는 첫 관문이기에 쉽진 않았지만 지난 21년 11월에 traffic control을 이용해서 점진적으로 트래픽을 새로운 클라이언트 서버로 전환하였고 11월 26일에 100% 전환하여 현재 안정적으로 서비스가 되고 있습니다.
