
안녕하세요. 오늘의집 데이터 엔지니어 델피입니다. 지난 4월 작성했던 <버킷플레이스 Airflow 도입기 (클릭)> 에 이어 이번에는 '검색기능 개발기'로 찾아왔습니다.
검색 내재화, 급격한 성장이 불러온 새로운 이슈
과거 오늘의집은 외부 업체의 검색엔진을 사용하고 있었습니다. 서비스가 빠르게 성장하고 있는 상황에서 외부 검색솔루션은 가장 쉽게 검색기능을 제공할 수 있는 방법이었지만 오늘의집이 점점 커지고 다양한 검색 기능의 요청이 생기면서 확장성의 한계에 부딪히게 되었습니다. 검색해야 하는 문서 수도, 검색을 사용하는 사용자 수도 늘어나면서 빠른 Scale Up과 Scale Out이, 검색 피처 추가나 가중치 조절 등에 자유도가 떨어진다는 점이 문제가 되고 있었죠.

검색 내재화 프로젝트의 시작
시작은 간단했습니다. 당장 프로덕션에 사용할 게 아니었기 때문에 업무시간 틈틈이 Elasticsearch를 사용하여 간단하게 PoC를 만들어 보고, 기존 솔루션과 비교해보고 있던 상황이었습니다. 초기 버전은 기존 검색엔진과 최대한 같은 결과가 나오게 만드는 것이 목표였기 때문에 인덱싱 되는 문서, 가중치, 사전 등 검색에 영향을 주는 피처들을 동일하게 가져가고 검색 쿼리도 최대한 비슷하게 작성했습니다.
검색엔진으로 Elasticsearch를 사용하면서 형태소 분석기는 Elasticsearch에서 공식 지원하는 Nori 분석기를 사용하였고, 쿼리는 Function Score를 바탕으로 기존 검색엔진과 동일한 피처에 동일한 가중치를 주면서 시작하였습니다. 그 결과 기본적인 쿼리에 대해서는 비슷한 검색결과가 나왔지만, 오늘의집 특성상 들어오는 인테리어 관련 쿼리들에 대해서는 천차만별의 검색결과가 나타나 많은 작업이 필요했습니다.
그리고 그 즈음 저는 훈련소에 가게 되었습니다. 산업기능요원으로 오늘의집에 복무 중이기 때문에 짧은 기간 훈련소에 가야만 했는데요. 다행히도(?) 프론트엔드 개발을 하고 계신 프레코 님과 같이 가게 되어서 맘 편히 다녀올 수 있었습니다.

제가 없으면 멈출 것만 같았던 회사는 빠르게 돌아가고 있었습니다. 제가 만들어두고 간 검색 데모를 보고 당황(?)하셨는지 회사에 돌아오니 새로 오신 검색팀의 PO 제이비 님이 저를 기다리고 계셨습니다.

훈련소에서 나온 이후 검색엔진 개선은 빠르게 진행되었습니다. 형태소 분석기를 개선하고 사전, 가중치, 쿼리 모두 끝없이 변경하고 비교하면서, 변경의 굴레에 들어가게 되었습니다.

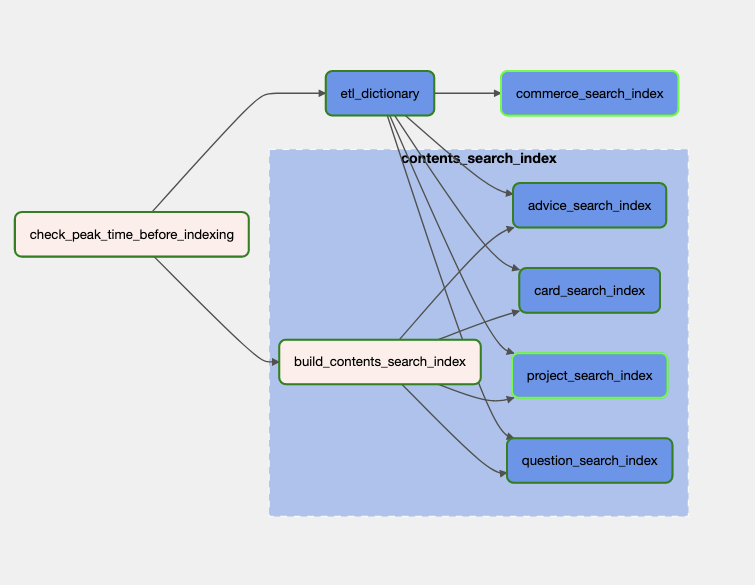

검색 서버 또한 새로 개발해야 했는데요. 들어온 쿼리를 전처리해서 Elasticsearch에 쿼리를 하는 역할을 수행해야 했습니다. 앞으로는 쿼리분석, 쿼리 → 카테고리, 오타교정, 검색결과 리랭킹 등 다양한 서비스와 통신하게 될 것으로 계획하면서 오늘의집 MSA Backend stack에 맞춰 gRPC로 개발했습니다.

그렇게 검색서버를 배포하고 기존 검색엔진을 교체하고 나니 오늘의집 검색엔진을 내재화하는데 성공했습니다! 가 아니고, 사실 중간중간 크고 작은 문제가 굉장히 많았습니다.
<오늘의집 실험 플랫폼 (클릭)>에서 소개해드렸던 실험 플랫폼을 통해 트래픽을 컨트롤하며 천천히 검색엔진을 전환했는데요. 그 과정에서 크고 작은 다양한 문제를 발견하였습니다. 그중에는 이미 해결한 문제도 있지만 아직 해결하지 못한 문제도 있는데요. 그 시행착오 중 일부를 아래와 같이 정리해보았습니다. 혹시 보다가 훈수를 두고 싶으신 분들이 계시다면 저희가 두 팔 벌려 환영해 드리겠습니다.
👉 검색/추천 Backend Developer 채용 공고 자세히 보기
문제 1. 성능
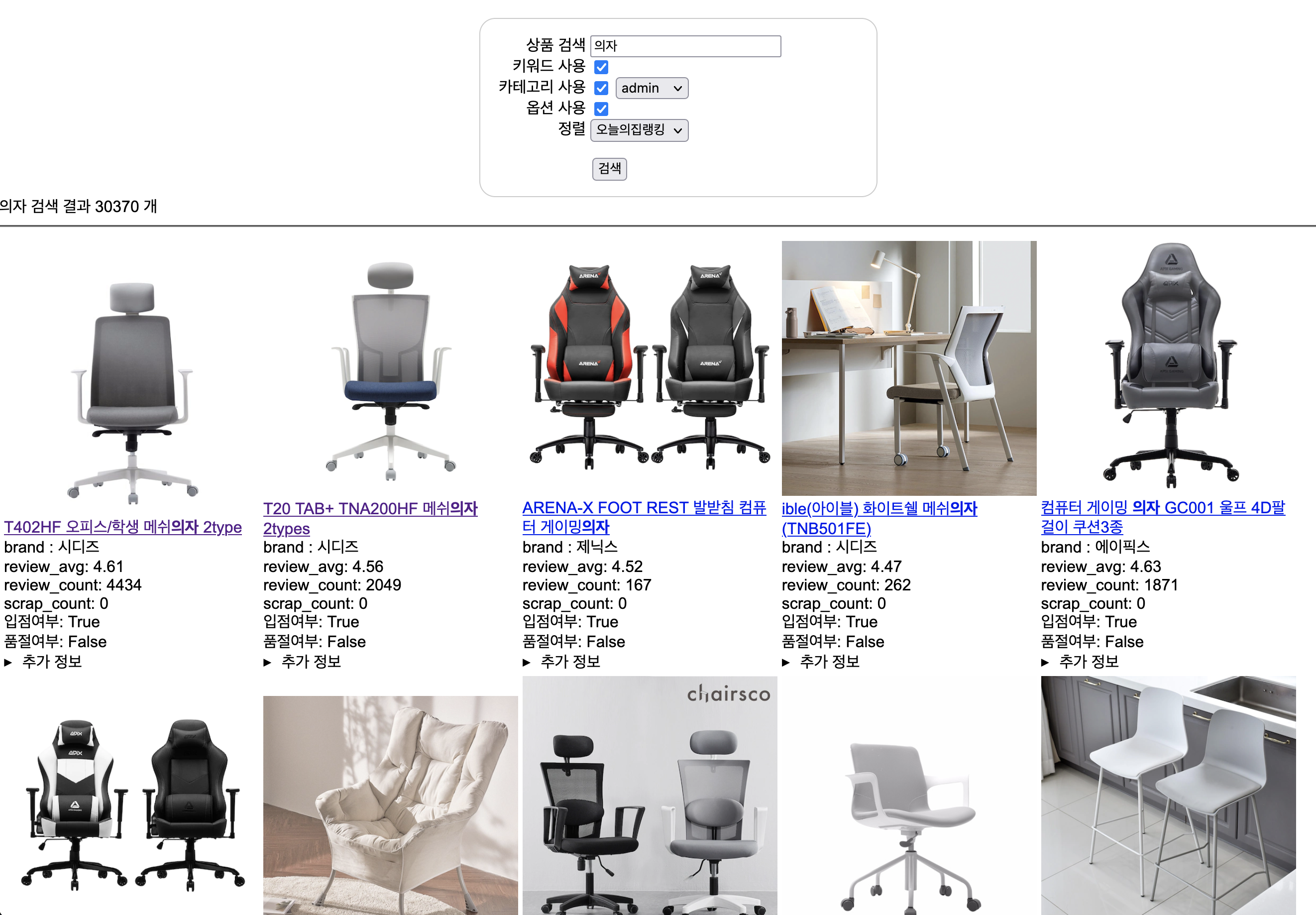
오늘의집 커머스의 핵심 기능 중 하나는 ‘필터’입니다. 다양한 속성들이 다이내믹하게 필터로 나타나면서 사용자의 검색경험을 극대화해주는 기능인데요. 검색에서도 필터를 노출하기 위해 저는 Aggregation 쿼리를 이용하여 검색결과에 해당하는 다양한 필터들을 찾아서 보여줄 수 있도록 제작하였습니다.
하지만 배포 전 Load Testing에서는 문제가 없었던 이 쿼리가 Production에 나간 후 좀 있다가 급격하게 느려지는 현상을 보이기 시작했습니다. 또 이상하게도 어떤 날은 P99 Latency가 20ms로, 어떤 날은 900ms 으로 왔다갔다 하는 이상한 현상도 일어났습니다.

Elasticsearch의 샤드수 최적화를 의심하면서 DevOps팀에 Production과 같은 스펙의 Testbed를 요청해서 테스트를 해보기로 했습니다. 이런 일이 있을 줄 알고(?) 확장성을 고려해서 Kubernetes에 모든 인프라를 구축해둔 덕분에 매우 편하게 Testbed를 구축할 수 있었고, Load Testing을 하면서 원인을 빠르게 찾아볼 수 있었습니다.
샤드, 레플리카 설정을 건드려봐도 현상 재현이 어렵고, 성능에도 큰 차이가 나지 않아 Elasticsearch 아래에 Lucene 인덱스의 설정을 확인해보면서 문제를 발견할 수 있었는데요. 원인은 Lucene Segment의 수에 있었습니다. Elasticsearch는 Lucene Segment에 새로운 문서를 쓰고, 적절한 간격으로 Segment를 Merge 해주고 있습니다. Segment 수가 많으면 많을수록 쓰기 성능은 좋아지지만 모든 Segment를 검색해야 해서 검색의 성능은 느려지는데요. 이 숫자가 왔다갔다 하면서 성능의 차이가 나타나고 있었던 것입니다.

오늘의집 검색 파이프라인에서는 배치(Batch)로 새로운 문서를 넣어주고 있는데 이때 마지막에 몇 개의 Segment가 있는지에 따라 검색성능에 큰 차이가 나타난다는 것을 알 수 있었습니다.
빠르게 Load Testing을 해보고 문제의 원인임을 정확히 확인한 다음 Production까지 Segment 최적화를 적용해보았습니다.
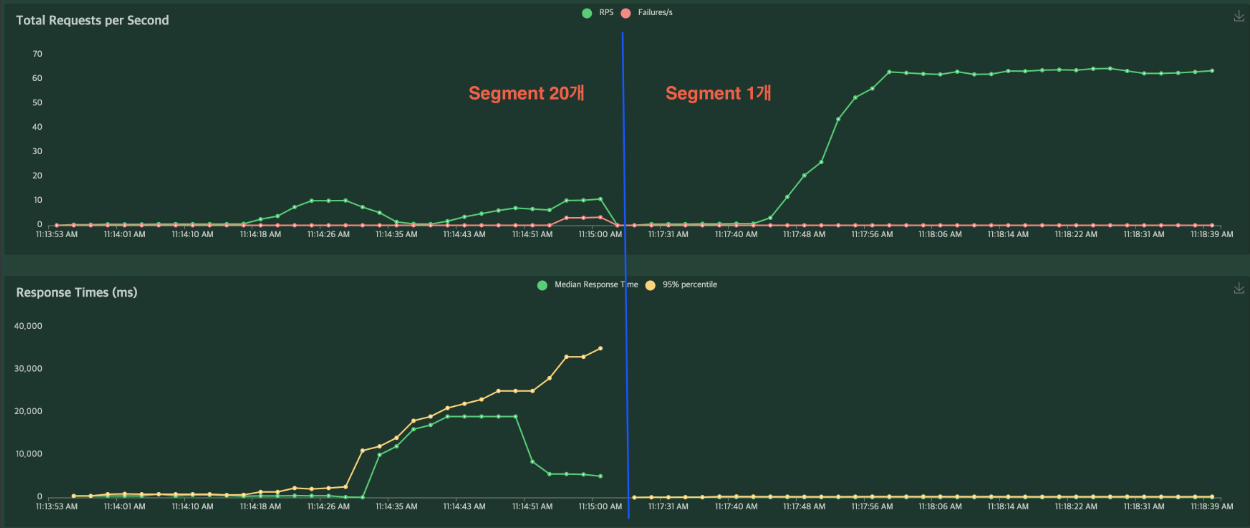
그 결과 P99 Latency를 17ms 수준으로 낮추고, Latency도 안정화할 수 있었습니다.

문제 2. Nori 형태소 분석기의 인덱스 생성 실패
Elasticsearch에 인덱스를 생성하고 수많은 신조어, 동의어 사전을 넣어주면서 검색 결과를 최적화 하고 있던 어느 날! 인덱스 생성에 실패하게 됩니다.
찾아보니 ‘&’ 문자가 포함된 신조어가 형태소 분석기에 의해 이상하게 분석되면서 동의어 생성에 실패하고 있었습니다.
{
"type" : "parse_exception",
"reason" : "parse_exception: Invalid synonym rule at line 1"
}
오늘의집 검색에서는 Nori 형태소 분석기와 함께 POS필터를 사용해서 커스텀 분석기를 만들어 사용하고 있는데요. 처음에는 형태소 태그를 바탕으로 인덱스에서 제거해주는 이 POS 필터가 ‘&’ 문자를 없애버려서 문제가 발생한다고 생각했습니다.

품사 태그 표를 뚫어져라 쳐다봐도 잘 모르겠고, 여러 태그를 필터에 넣었다 뺐다 하며 테스트를 해 봐도 해결이 되지 않아서 Nori 자체의 문제를 의심하게 되었습니다.
바로 Elasticsearch의 _analyze 기능을 이용하여 테스트 해보았습니다.
POST /_analyze
{
"analyzer": "nori",
"text": "&delphi"
}
결과
{
"tokens" : [
{
"token" : "delphi",
"start_offset" : 1,
"end_offset" : 10,
"type" : "word",
"position" : 0
}
]
}
아니 이게 무슨 일이죠? 왜 Nori가 ‘&’를 빼버리고 있는 것인가요? (😦진작 이것부터 테스트 했어야..)
화들짝 놀라서 다른 특수문자들도 테스트해 보았습니다.
POST /_analyze
{
"analyzer": "nori",
"text": "! @ # $ % ^ & * ( ) _ + 🍕"
}
결과
{
"tokens" : [
{
"token" : """🍕""",
"start_offset" : 24,
"end_offset" : 26,
"type" : "word",
"position" : 0
}
]
}
테스트 결과 피자 한 조각🍕 만 살아남는 모습을 확인할 수 있었습니다. Nori가 POS 필터까지 가기도 전에 특수문자들을 없애고 있었던 것이죠.

공식 문서를 보다 보니 위와 같은 설정이 있었습니다. (왜 default가 true 일까요? 엉엉😢) 역시 개발을 할 때는 모든 문서를 꼼꼼하게 읽어보는 것이 중요하다는 사실을 다시 한 번 깨달을 수 있었습니다.
이 설정을 추가해서 인덱스를 생성하면
POST /_analyze
{
"analyzer": "nori",
"text": "! @ # $ % ^ & * ( ) _ + 🍕"
}
결과
{
"tokens" : [
{
"token" : "! @ # $ % ^ & * ( ) _ + ",
"start_offset" : 0,
"end_offset" : 24,
"type" : "word",
"position" : 0
},
{
"token" : """🍕""",
"start_offset" : 24,
"end_offset" : 26,
"type" : "word",
"position" : 1
}
]
}
특수문자들이 잘 살아있는 모습을 볼 수 있습니다
문제 3. 대문자, 소문자, 스웨덴 문자?

정확한 검색을 위해서는 형태소 또한 정확하게 분석돼야 합니다. 스웨덴 문자 매핑, 대문자, 소문자 통일과 같은 작업은 형태소 분석 전에 먼저 되어야 하는데요. Elasticsearch에는 Lowercase Token Filter를 제공해서 사용하고 있었는데 형태소 분석 전이 아닌 후에 적용이 되어 원하는 방향으로 형태소 분석이 안되고 있는 상황이었습니다.
찾아보니 원인은 간단했는데요. Elasticsearch의 Analyzer가 문서를 분석하는 순서에 있었습니다. Elasticsearch의 Analyzer는 Character Filter ⇒ Tokenizer ⇒ Token Filter 순으로 적용됩니다. Tokenizer에서 Nori가 형태소 단위로 Token을 생성해 주고, Token Filter에서 각 Token에 처리를 해주는 것이죠. Lowercase Token Filter는 형태소 분석이 다 된 각 형태소를 소문자화해주고 있었던 것입니다.

형태소 분석 전 문자에 전처리를 해주는 Character Filter 단계에서 소문자화, 스웨덴문자 매핑을 처리해주면서 문제를 해결할 수 있었습니다.
문제4. 개발환경 세팅
개발환경 세팅도 문제였습니다. 물론 개인의 개발환경이 아니라 검색엔진에 새로운 피처를 넣고, 검색결과를 비교 할 수 있는 개발환경이 없다는 게 문제였습니다. 빠르게 검색 쿼리를 바꿔볼 수 있고, 새로운 데이터를 넣어 기존의 검색결과와 한눈에 쉽게 비교할 수 있는 개발환경이 필요했습니다.
이 문제를 해결하기 위해 오늘의집 DevOps팀에서 만들어준 Preview기능을 활용하기로 했는데요. 이는 코드를 작성하고 Pr을 날리면 자동으로 Preview서버를 Kubernetes에 배포해주는 기능입니다.

이렇게 생성된 Preview 검색서버의 결과를 Production 검색서버 결과와 간단하게 비교해주면 변경된 쿼리나 데이터의 차이를 볼 수 있습니다. 이 차이를 한눈에 비교할 수 있게 HTML table로 그려주면 끝!

검색결과를 한눈에 비교할 수 있는 나름 최선의 개발환경(?)을 세팅했다고 생각합니다. 혹시라도 위 이미지의 UI가 마음에 들지 않으신다면 검색 프론트엔드 개발자 포지션에 지원해주세요! 🙌
👉 Search Web Frontend Developer 채용 공고 자세히 보기
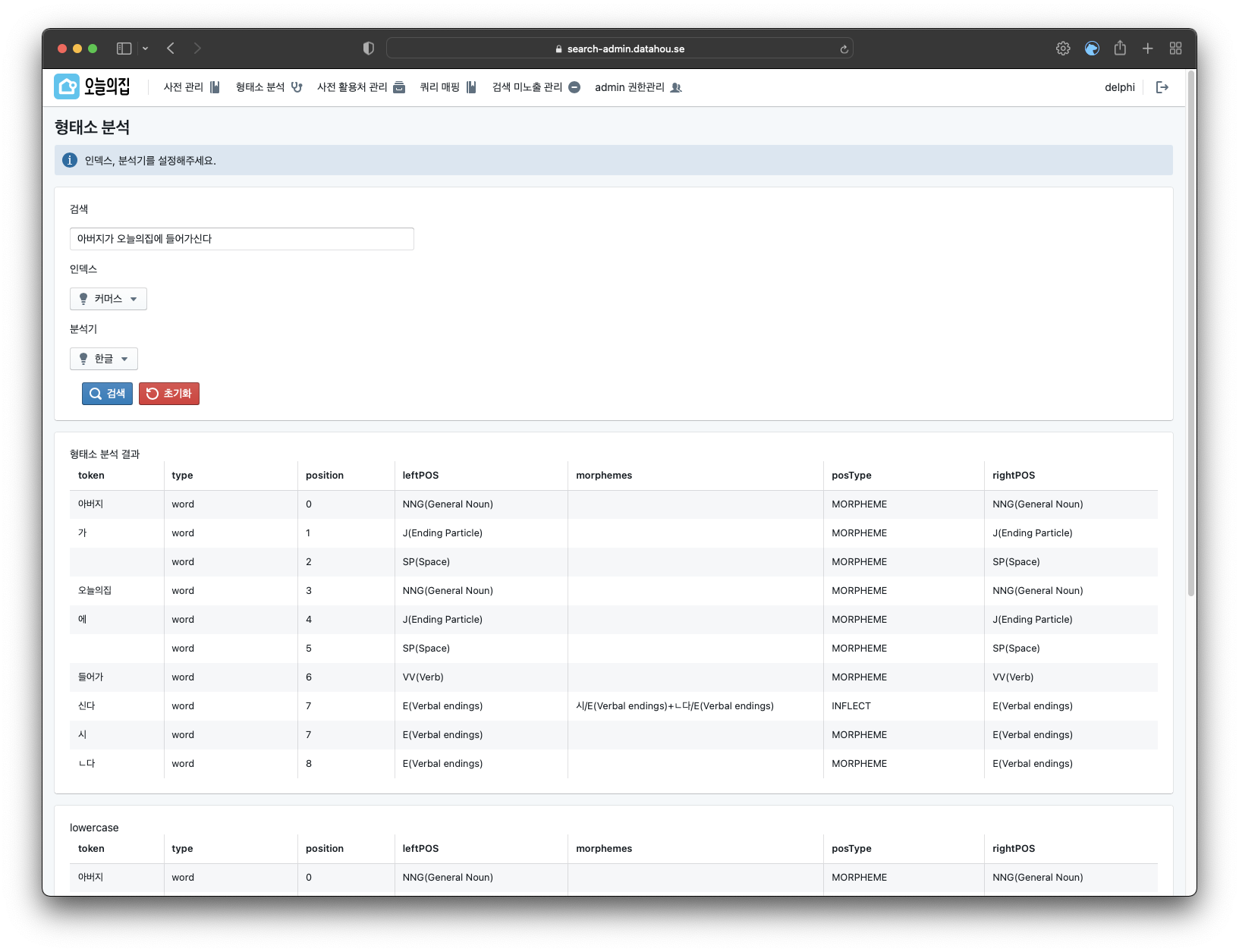
문제5. 어드민 개발

어드민 기획이 도착했을 때만 해도 저는 프론트엔드라고는 TODO app, React 튜토리얼에 Tic Tac Toe 게임만 만들어 본 데이터 엔지니어였습니다. 이런 상황에서 Tech 리더 진식 님이 이미 만들어져 있는 React Admin 프레임워크를 사용하는 방법도 있다고 제안해주셔서 도전해보기로 하였습니다.
당시 오늘의집이 물류를 새롭게 시작하고 있던 때라 물류 어드민을 만드신 노을 님에게도 도움을 받아서 개발을 시작할 수 있었습니다. (하지만 물류어드민과 검색어드민이 비슷해 보인다면 착각입니다ㅎ)

그렇게 어떻게 했는지 기억은 잘 나지 않지만(?) 우여곡절 끝에 검색어드민을 만들 수 있었습니다.
문제 6. 데이터 파이프라인
오늘의집은 커머스, 콘텐츠를 아우르는 다양한 데이터를 가지고 있습니다. 조금 과장하자면 ‘쿠팡+인스타그램’ 정도의 느낌이죠. 검색의 입장에서는 전혀 다른 성격의 다양한 데이터를 처리해야 한다는 어려움이 있는데요. 다시 말해 커머스 데이터를 Elasticsearch에 넣기까지의 전처리와 오늘의집의 콘텐츠 데이터를 Elasticsearch에 넣기까지의 전처리가 전혀 다른 형태가 되는 것이라고 할 수 있습니다.
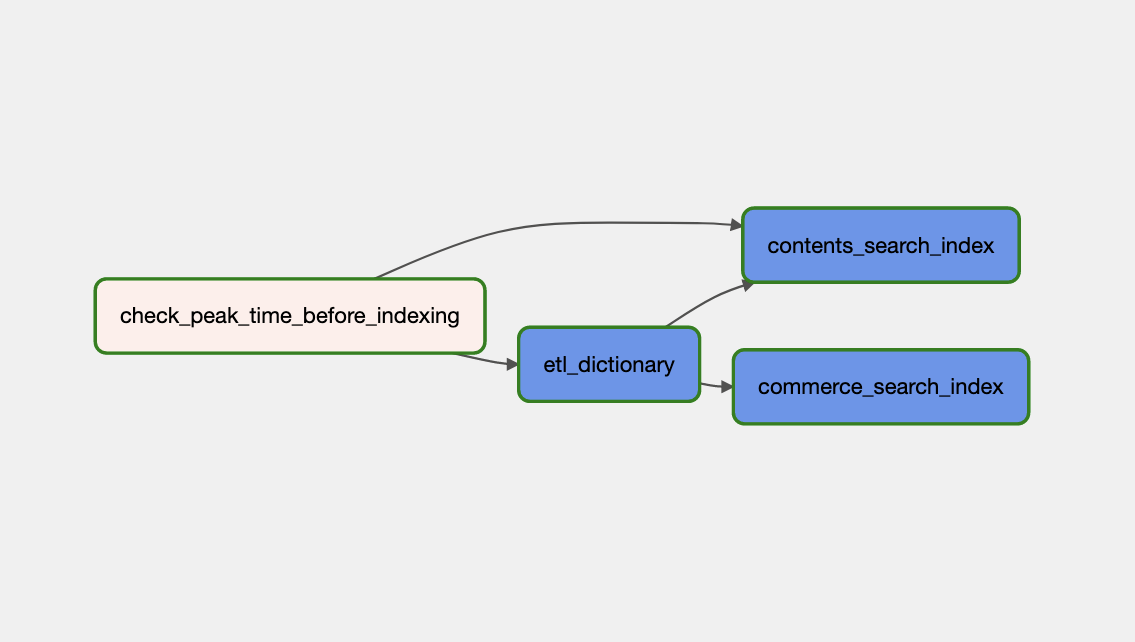
데이터 엔지니어의 본분을 무시할 수 없어서 저는 이 과정을 배치(Batch)로 만들었습니다. 커머스와 콘텐츠를 각각의 다른 Airflow Task로 만들어서 완전히 다른 파이프라인이 되도록 했습니다. 이렇게 배치로 인덱싱하면 변화를 적용하기 간단하고, Airflow를 이용한 각 Task 별 재실행이나 모니터링 또한 간단해져 보다 빠르고 편하게 개발할 수 있었습니다.
물론, 배치의 특성상 새로운 데이터가 검색에 반영되기까지 딜레이가 존재할 수 밖에 없는데 이 딜레이를 줄이고 스트리밍이나 실시간으로 인덱싱 할 수 있는 파이프라인을 개발하는 것은 앞으로 해결해야 할 과제입니다.
마치며
이처럼 크고 작은 문제를 해결하면서 외부 솔루션을 사용하던 검색을 100% 내재화할 수 있었습니다. 지금 생각하면 문서만 잘 읽었어도 피할 수 있었던 문제도 있었고, ‘왜 저렇게 했었지?’ 싶은 부분도 있지만 일단은 프로젝트를 나름 성공적으로 끝낸 것 같아 뿌듯합니다! (검색팀 모두 너무 고생많았습니다 👍)
검색을 내재화하면서 기존 검색엔진의 확장성 문제를 대부분 해결했습니다. 필터 기능을 사용하기 위한 과정을 하나로 통합하면서 응답 속도와 안정성을 개선하였습니다. 검색 피처를 추가하고 실험하기 쉬운 환경으로 만들어서 오늘의집의 검색도 더 고도화할 수 있는 기반을 다져두었습니다. 실제로 벌써 몇몇 새로운 검색 피처를 개발하여 반영하기도 하였고, 앞으로도 더 많은 피처 개발을 계획하고 있습니다.
검색 내재화는 개인적으로도 많은 성장을 할 수 있었던 프로젝트였습니다. Airflow를 도입하면서 가볍게만 만져보았던 Kubernetes 환경을 본격적으로 사용해 볼 수 있었고, 백엔드와 프론트엔드 개발까지 경험하며 더 많은 것을 배울 수 있었습니다. 그동안 데이터 엔지니어로서 사용자들에게 바로 영향을 주는 개발을 할 기회가 적었는데 검색은 하나하나의 변화가 사용자들에게 크게 노출이 되어서 그 또한 재미있었습니다.
물론 아직 개선해야 할 점과 고도화할 수 있는 부분도 많습니다. 앞으로도 더 빠르고 정확하며 똑똑한 오늘의집 검색 서비스를 목표로 계속 발전해 나갈 예정입니다.
