
2부. 비슷한 상품 (커머스)
지난번에 포스팅한 1부 ‘비슷한 공간’에 이어 이번 포스팅에선 ‘비슷한 상품’이란 서비스를 위한 모델링 문제를 소개하고자 합니다. (‘비슷한 공간’ 포스팅 다시 보기)
‘비슷한 상품' 서비스는 상품 상세 페이지에서 해당 상품과 유사한 상품들을 추천하는 서비스입니다. ‘비슷한 공간’ 서비스와 다른 점은 1) 시드 이미지에 해당하는 상품과 동일한 카테고리 안의 상품들을 추천해 주어야 하고, 2)세부 카테고리(leaf category)뿐만 아니라 category taxonomy 상 유사 카테고리 안의 상품도 같이 고려해야 한다는 점입니다.
이 문제를 풀기 위해 우선 상품 간의 유사도를 평가할 Feature를 선정했고 크게 두 가지 방식 - Classification과 Metric Learning - 으로 Feature Embedding을 학습시켜볼 수 있었습니다 [5]. Classification이 Item을 특정 Class로 분류하고 해당 Class로 Embedding 시키는 학습 방법이라면, Metric Learning은 같은 Item이면 Positive Pair로, 다르면 Negative Pair로 지정하여 Positive는 Embedding Feature 간의 거리를 가깝게 Negative는 멀게 학습하는 방식입니다.
오늘의집 커머스 데이터안에서는 거의 매일 새로운 Unseen Class(기존에 보지 못했던 상품)가 생길 수 있습니다. 새로 생성된 Unseen Class는 기존 Class에 비해 Classification을 학습할 만큼의 많은 양의 Annotation을 취득하기 어렵습니다. 또한 Classification 학습 방법은 새로운 Class가 생길 때마다 최종 Layer의 Dimension을 바꿔줘야하는 단점이 있습니다. 위와 같은 커머스 데이터의 특성 때문에 유지 보수 및 확장성을 고려하여 최종적으로 Metric Learning 기반의 학습 방식을 선정하게 되었습니다

Data
학습데이터를 구축하는 과정을 살펴보겠습니다. Metric Learning을 위한 학습데이터로 오픈소스 데이터인 Stanford Online Products를 사용하였습니다.

Stanford Online Products (SOP) 데이터셋은 22,634 Class와 120,053개의 상품 이미지로 구성되어 있는데요. 그중에서 11,318 Class (59,551개 이미지)는 학습용으로, 11,316 Class (60,502개 이미지)는 테스트 데이터로 사용됩니다. 일반적인 학습/테스트 데이터 비율보다 테스트 데이터의 비율이 높기 때문에 테스트 데이터 중 일부를 학습데이터에 포함시켜 좀 더 성능을 높여 사용할 수 있습니다.
SOP에서 제공하는 데이터의 Class가 다양하지만, 오늘의집 데이터를 전부 커버하기에는 한계가 있습니다. 따라서, 좀 더 높은 성능을 위해 오늘의집 이미지 데이터를 오픈소스 데이터셋과 혼합하여 Transfer Learning을 진행하였습니다.
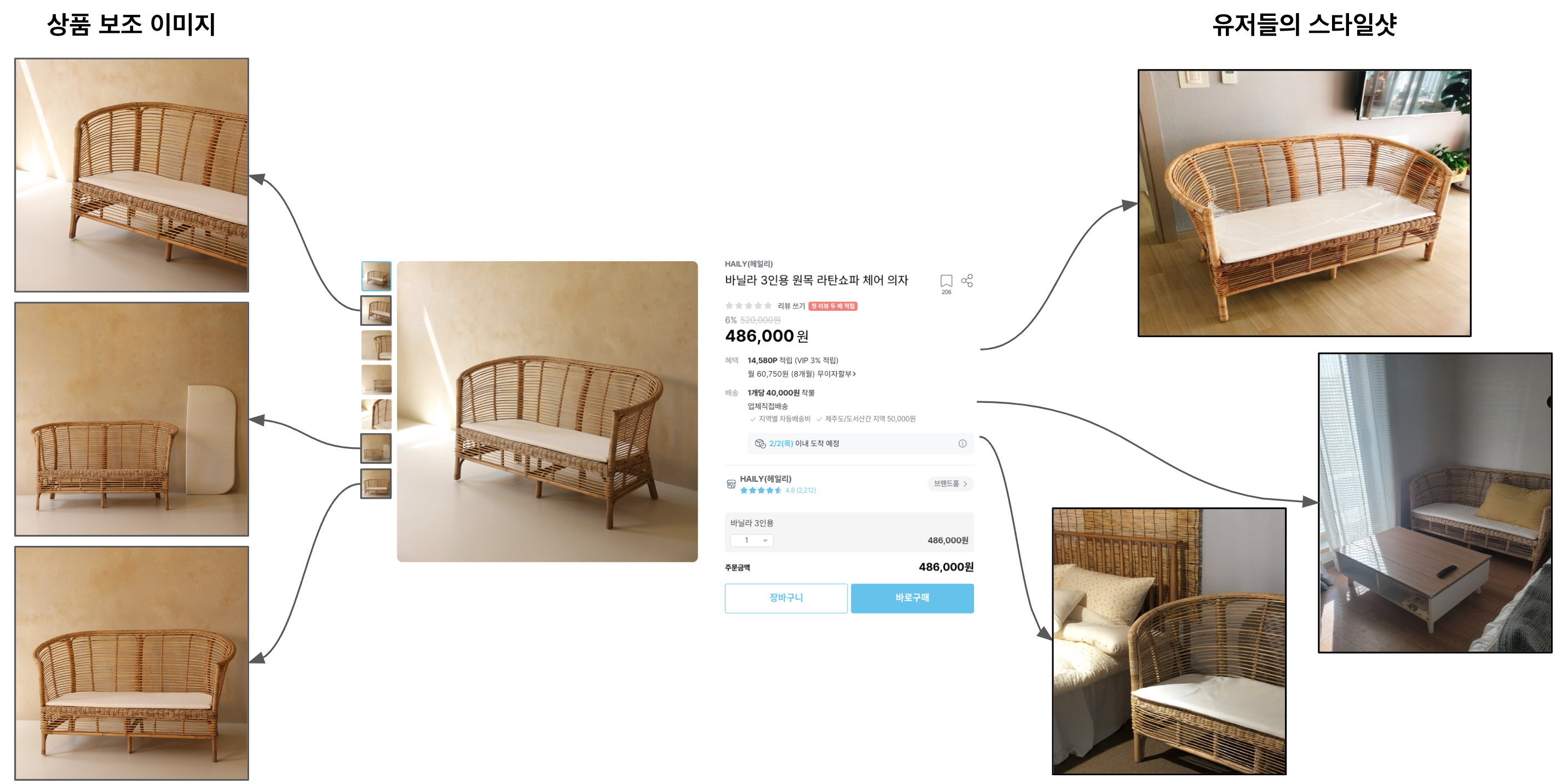

이미지 Cluster(위에 언급한 Class와 동일한 Set을 의미. Metric Learning 학습 시, Class단위를 Cluster로 표현)를 만드는 방법은 크게 두 가지로, 같은 상품의 유사한 이미지를 Cluster로 묶거나 상품 이미지에 대한 유저들의 스타일샷을 활용하는 방법입니다. <br></br>
Metric learning
저희가 선택한 Metric Learning 모델은 CVPR2022에 소개된 SOTA 모델인 Hyperbolic Vision Transformers입니다 [6]. 여러 Image Retrieval에서 좋은 성능을 보였으며, 특히 오늘의집 데이터 도메인과 유사한 온라인 상품 데이터셋인 SOP(Stanford Online Products)에서 좋은 성능을 보인 모델입니다.
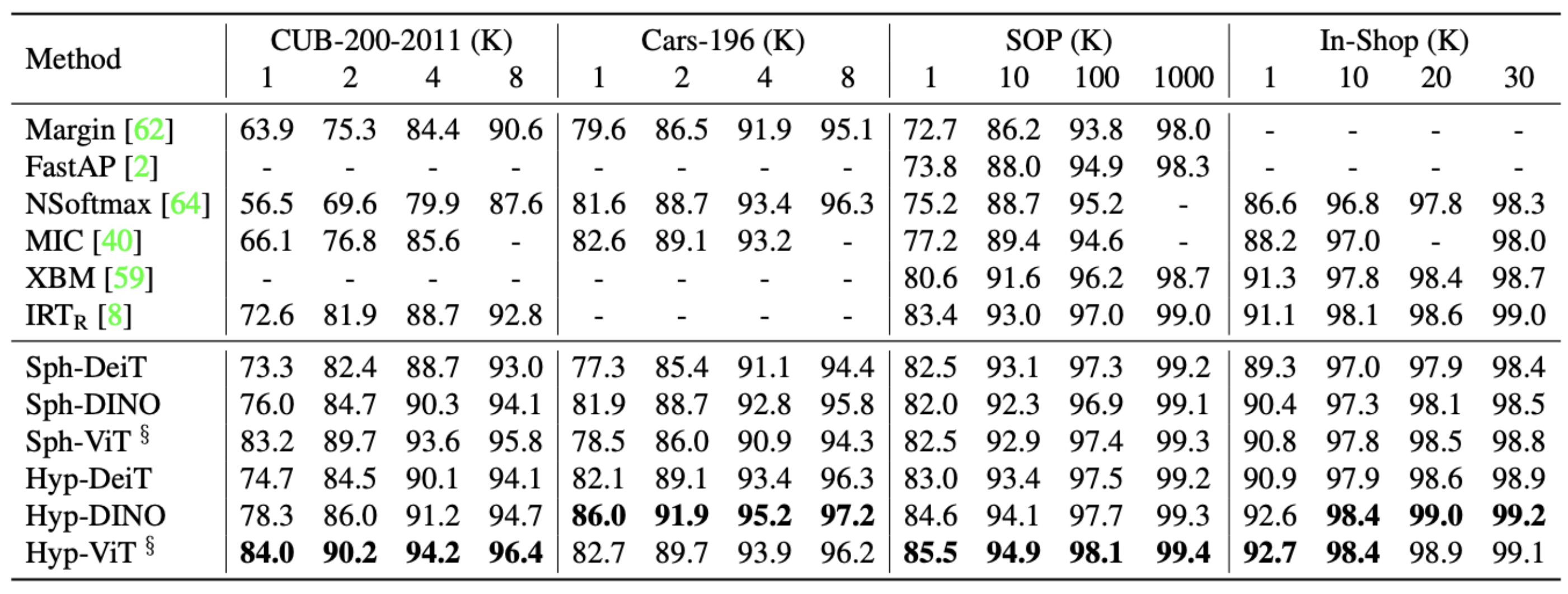
학습 기법은 일반적인 Metric Learning과 같이 Embedding Vector 간의 거리를 Loss로 학습하였습니다. 주요 Contribution은 Poincaré Ball이라는 Embedding 공간을 사용해 Hyperbolic Distance로 정의된 Pairwise Cross-entropy Loss를 사용한 점, 높은 분류 성능을 보이는 Transformer 계열의 Backbone을 잘 Fine-tuning 했다는 점입니다.
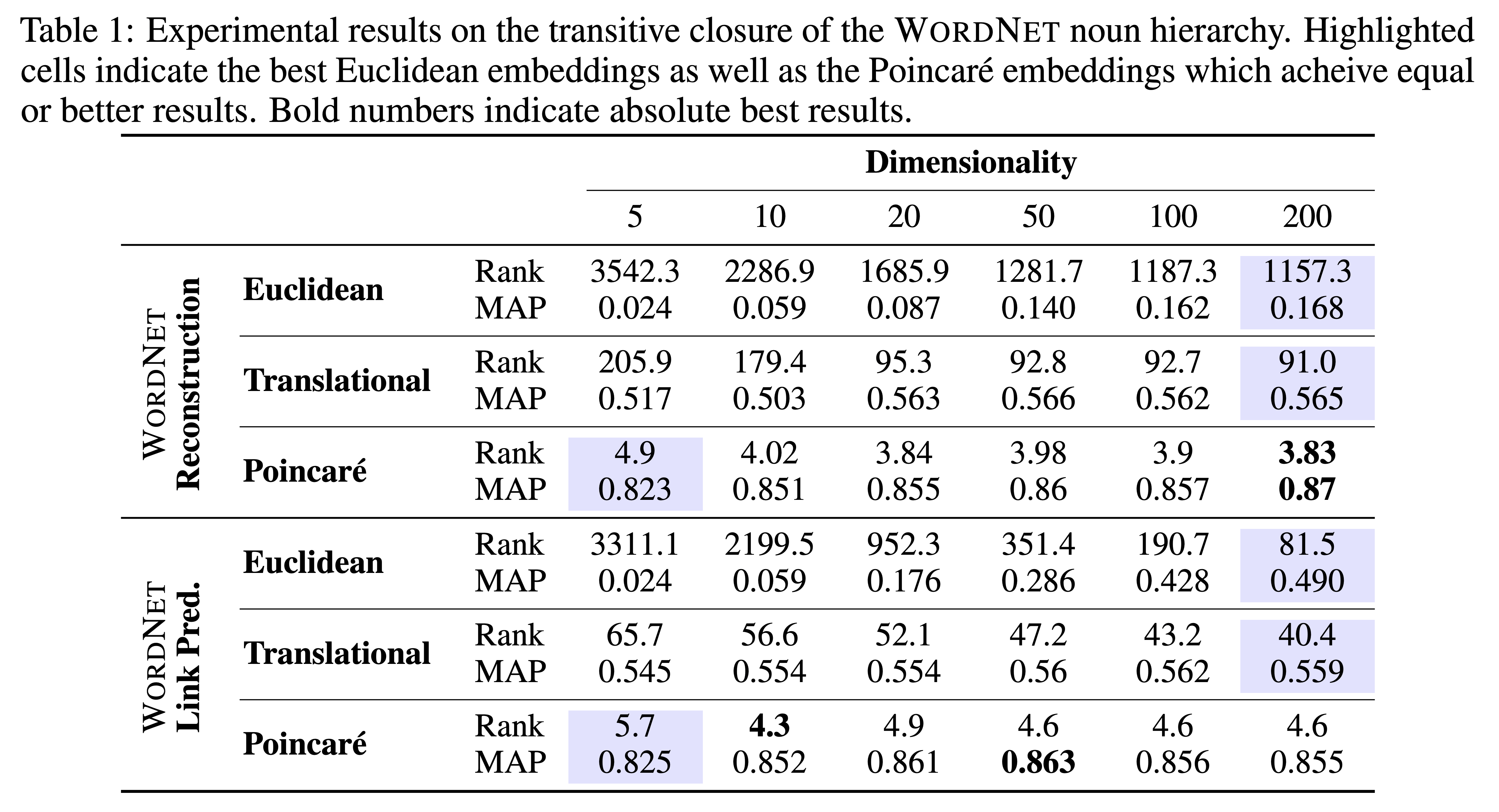
특히 논문에서 사용한 Poincaré Embeddings이 Cluster간의 Hierarchical 관계에서 좋은 성능을 보이고, 또 적은 Embedding Dimension으로도 좋은 성능을 내고 있다고 설명하고 있어 계층 구조를 갖는 저희 상품이미지 데이터셋에 어울리고 Computational Resource를 절약할 수 있다는 측면에서 적합한 모델로 선정하게 되었습니다 [7, 8]. 실제로 해당 모델을 통해 feature dimension을 1024에서 128로 줄이면서도 좋은 성능을 유지할 수 있었습니다.
Metric Learning에서 학습된 상품 이미지의 Feature를 추출하면, 비슷한 공간 때와 마찬가지로 인덱싱을 통해 비슷한 상품의 추천 결과를 생성합니다. 인덱싱 방식은 유사하지만, 추천 결과에 대한 Service Dependency에 의해 비슷한 공간과 비슷한 상품에 서로 다른 Post Processing이 적용됩니다.
Post-processing
비슷한 상품
실제 서비스에서는 수백 수천만의 상품들이 있고, 이미지 Feature에만 의존해 가장 비슷한 상품을 찾는 것은 성능과 속도면에서 매우 어려운 문제입니다. 때문에 저희는 상품의 판매 효용성을 높이기 위해 가지고 있는 상품 Category 정보를 활용합니다.
상품 카테고리의 Taxonomy는 트리 구조를 가지고 있으며 Depth가 깊어짐에 따라 세부 카테고리를 갖습니다. 또한 제품마다 assign된 카테고리가 해당 트리에 존재합니다. 처음엔 해당 카테고리 내에서 인덱싱과 탐색을 수행하고, 조건을 만족하는 제품이 너무 적을 경우 부모 카테고리 노드에서 묶인 다른 sibling category들에서 추가 탐색을 합니다.
Evaluation
기존 모델을 대체하기 위해 신규 모델에 대한 비교 및 평가가 이루어져야 합니다. 저희는 다음과 같이 아래의 세 단계를 통해 모델 평가를 진행하였습니다.
- 정성적 평가
- 정량적 평가 (Offline Test)
- AB test (Online Test)
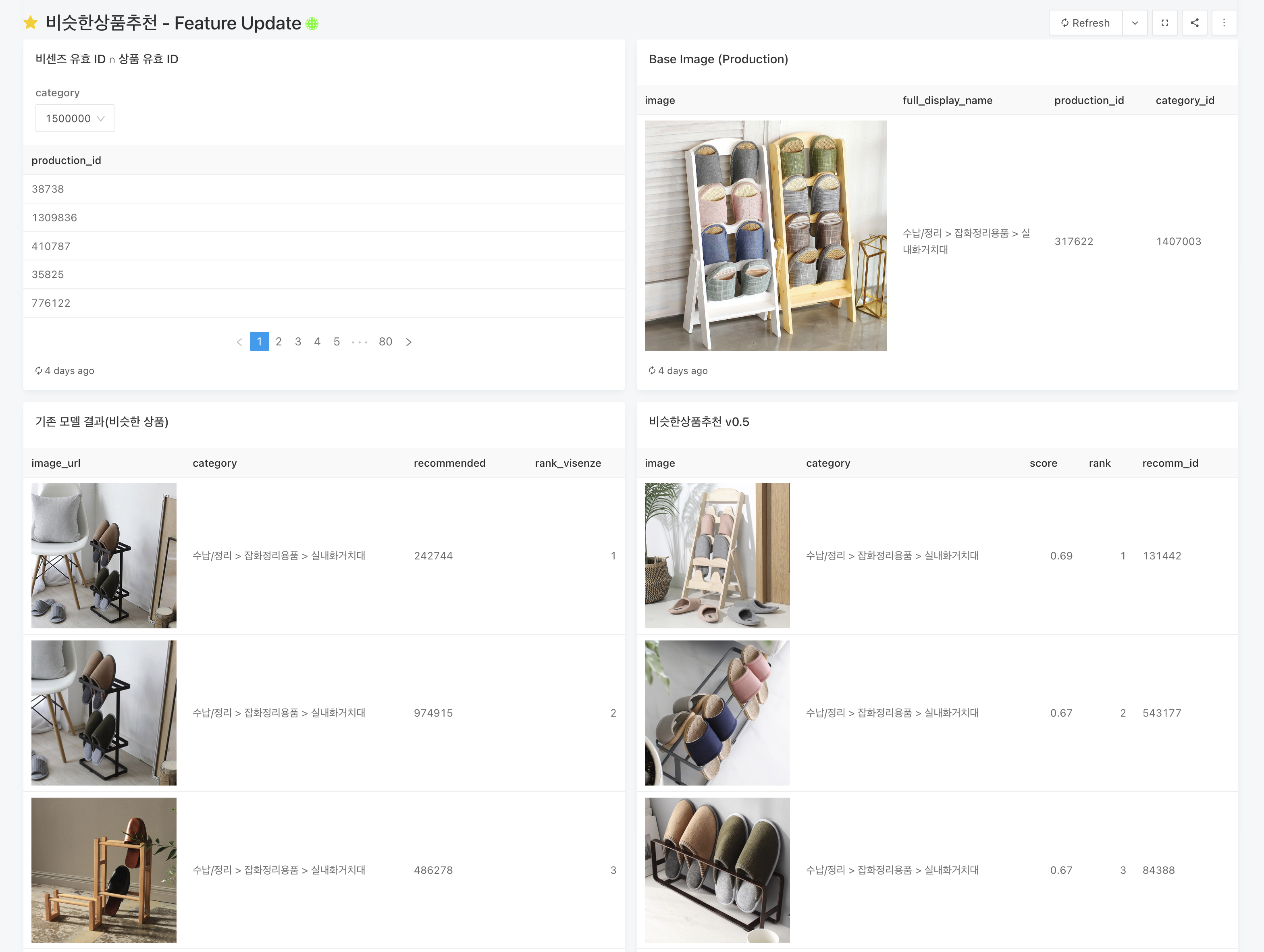
정성적 평가
정성적 평가는 데모 페이지 생성 후, 내부 개발자들 및 관련 협업자들에게 공유하여 피드백을 받습니다. 추천되는 이미지가 실제로 사람들의 눈에 비슷한 이미지인지, 사람들이 클릭할만한 사진을 잘 추천해주고 있는지, 추천되는 사진 중 무의미한 중복은 없는지 등 수치로 환산할 수 없는 부분에 대한 정성적 평가를 진행합니다.
정량적 평가(Offline Test)
Offline Test는 사용자들의 클릭, 구매 히스토리 로그를 이용해 모델의 성능을 평가하는 방법입니다. 오늘의집 사용자가 특정 이미지를 클릭했을 때, 그 이미지에 대한 모델의 추천 결과 중 몇 개나 클릭했는지(Hit Ratio), 몇 번째에 있는 것을 클릭했는지(Mean Reciprocal Rank)에 대해 평가하고, 평가 결과와 기존 추천 결과를 비교하여 결과 수치가 동등한 수준인지 확인합니다. 그 외에도 추천의 다양성을 나타내는 지표인 Centrality Ratio(가장 많이 추천된 아이템 k개의 추천 수 / 전체 추천 수), 기존 추천 결과 Set과의 Match Rate 등을 확인함으로써 내재화 모델의 성능을 가늠할 수 있었습니다.
AB Test(Online Test)
마지막으로 실제 서비스에 도입했을 때의 성능 비교를 위해서 온라인으로 AB Test를 진행합니다. 오늘의집은 AB Test를 위한 실험 플랫폼인 XPC를 구축하여 데이터 기반의 의사결정을 진행하고 있습니다. XPC에서는 랜덤으로 지정된 A, B 실험군에 서로 다른 피쳐를 노출시켜 성공지표(Success Metric)를 비교합니다. 저희는 A그룹에 기존 솔루션의 추천 결과를, B그룹에는 신규모델의 유사 이미지 추천 결과를 노출시켰고, 성공지표로 Click Through Rate(CTR), Conversion Rate(CVR)를 검토하였습니다.
그 결과, 가드레일 지표가 되는 전체 지출이나 같은 지면에서 추천되고 있는 다른 구좌(같은 시리즈 상품, 인기 상품, 다른 고객이 함께 구매한 상품)와의 총 CTR이 떨어지지 않았고, B그룹에서 Impression과 Click이 각각 14.21%, 12.74% 증가함을 확인할 수 있었습니다. 결론적으로 B그룹을 Winner로 선정하고 “비슷한 상품” 영역을 내재화 모델로 성공적으로 대체하였습니다. <br></br>
Future Work
비슷한 공간과 비슷한 상품을 추천하는 이미지 유사도 모델을 개발했지만, 아직 개선할 수 있는 방안이 많이 남아 있습니다.
비슷한 상품 - 가격 등의 메타데이터 활용
비슷한 공간에서 중복 이미지를 제거하는 것처럼 비슷한 상품에서도 중복 이미지를 제거하는 로직을 추가할 수 있습니다. 다만, 이미지가 동일하더라도 판매되는 상품은 서로 다를 수 있고, 상품이 동일하더라도 가격 등의 주요 메타데이터 값이 다를 수 있으므로 해당 정보를 활용할 필요가 있습니다.
중복 이미지를 가진 상품의 경우
- 동일 제품, 다른 가격 - 더 저렴한 가격의 제품을 추천합니다.
- 다른 제품 - 특별한 이유가 없다면 모두 추천해주는 것이 합당합니다. 제품의 규격, 양에 따라 좀 더 살펴보고 싶은 제품이 존재할 것이기 때문입니다. 물론 이 부분은 제품 특성에 따라 세부적인 룰이 필요할 수도 있습니다.
또한, 이미지가 상품의 모든 정보를 포함하는 것이 아니므로 상품 자체의 유사도를 측정하기 위해 메타데이터를 적극적으로 활용할 수도 있습니다. 예를 들어, 비슷한 상품에서 단순히 Leaf Category부터 순차적으로 인덱싱과 탐색을 하는 것이 아니라 카테고리 간의 실질적인 유사도를 고려할 수 있습니다. 오늘의집의 상품 카테고리는 상당히 세분화되어 있는데, Parent Category(예. 잡화 정리 용품)가 동일하더라도 몇몇 Leaf Category는 매우 유사할 수 있고 (예. 실내화 거치대 - 신발장/정리대) 몇몇은 상당히 다를 수 있습니다(예. 실내화 거치대 - 이불 정리 용품). 유사한 상품을 찾아내기 위해 이러한 정보를 활용할 수도 있을 것입니다.
Indexing 최적화
유사한 공간 및 상품을 찾아내는 과정에서 인덱싱의 계산 비중이 상당합니다. 먼저 메모리 효율성을 위해 코드 최적화를 하였으며, 지금도 Cell Size 등 인덱싱 관련 파라미터들을 조절하는 방식으로 개선 작업을 꾸준히 진행하고 있습니다.
또한 현재 인덱싱을 위한 라이브러리로 Faiss를 사용하고 있지만 최적화를 위해 Milvus 등 다른 라이브러리를 활용하는 것도 고려 중입니다. 문제의 특성마다 탐색 속도, 인덱스 사이즈 등 여러 요소 중 어떠한 요소를 중점적으로 볼 것인지가 상이하고, 이에 따라 적합한 파라미터, 알고리즘 및 라이브러리가 다를 수 있기 때문에 다양한 시도를 해 보는 것이 필요합니다.
Reference
[5] Classification is a Strong Baseline for Deep Metric Learning, https://arxiv.org/pdf/1811.12649.pdf
[6] Hyperbolic Vision Transformers: Combining Improvements in Metric Learning, https://arxiv.org/abs/2203.10833
[7] Khrulkov, Valentin, et al. "Hyperbolic image embeddings." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[8] Nickel, Maximillian, and Douwe Kiela. "Poincaré embeddings for learning hierarchical representations." Advances in neural information processing systems 30 (2017).
